近年来,谷歌于 2018 年推出的 JAX 迎来了迅猛发展,很多研究者对其寄予厚望,希望它可以取代 TensorFlow 等众多深度学习框架。但 JAX 是否真的适合所有人使用呢?这篇文章对 JAX 的方方面面展开了深入探讨,希望可以给研究者选择深度学习框架时提供有益的参考。
自 2018 年底推出以来,JAX 的受欢迎程度一直在稳步提升。2020 年,DeepMind 宣布使用 JAX 来加速其研究。越来越多来自谷歌大脑(Google Brain)和其他机构的项目也都在使用 JAX。
目前,在 JAX 的 GitHub 项目主页,Star 量已经达到了 16.3k。

项目地址:https://github.com/google/jaxJAX 是一个非常有前途的项目,并且用户一直在稳步增长。JAX 已经在深度学习、机器人 / 控制系统、贝叶斯方法和科学模拟等诸多领域得到了广泛应用。
如此,是否意味着 JAX 也将成为下一个大型深度学习框架?近日,发表在 AssemblyAI 博客上的文章《Why You Should (or Shouldn't) Be Using JAX in 2022》中,作者 Ryan O'Connor 为我们深入解读了 JAX 的概念、使用 JAX 的理由以及是否应该使用 JAX 等。
JAX 简介
JAX 不是一个深度学习框架或库,其设计初衷也不是成为一个深度学习框架或库。简而言之,JAX 是一个包含可组合函数转换的数值计算库。正如我们所看到的,深度学习只是 JAX 功能的一小部分:

JAX 的定位科学计算(Scientific Computing)和函数转换(Function Transformations)的交叉融合,具有除训练深度学习模型以外的一系列能力,包括如下:
即时编译(Just-in-Time Compilation)
自动并行化(Automatic Parallelization)
自动向量化(Automatic Vectorization)
自动微分(Automatic Differentiation)
使用 JAX 的原因有哪些?
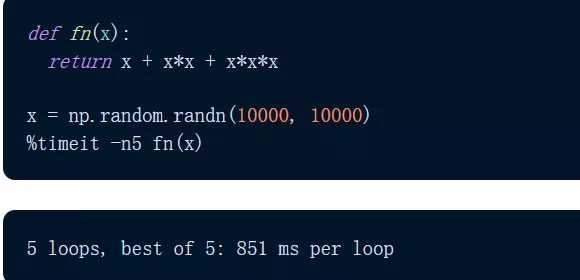
简而言之,是速度。这是 JAX 与任何用例相关的一种通用能力。让我们使用 NumPy 和 JAX 对矩阵的前三个幂求和(按元素)。
首先是 NumPy 实现。我们发现,该计算大约需要 851 毫秒。
然后使用 JAX 实现该计算: JAX 仅在 5.54 毫秒内执行完成该计算,速度是 NumPy 的 150 倍以上。
JAX 仅在 5.54 毫秒内执行完成该计算,速度是 NumPy 的 150 倍以上。
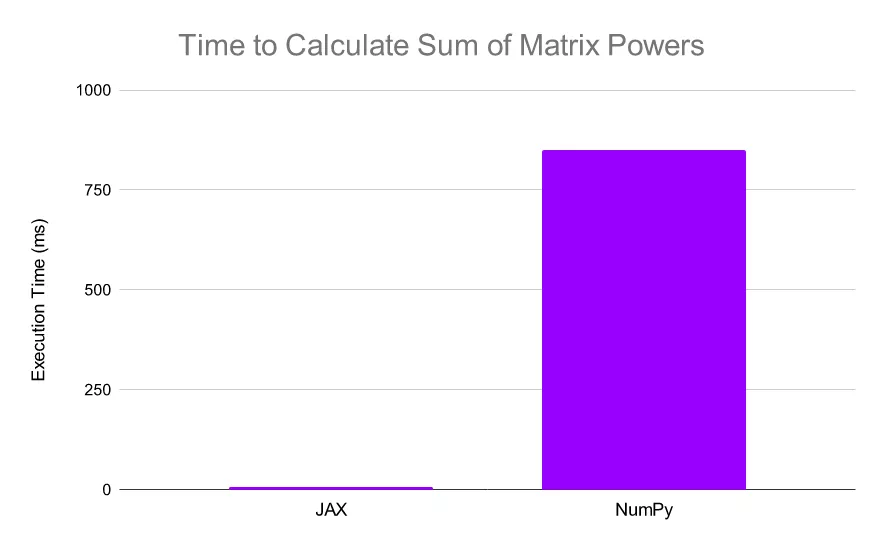
JAX 的速度比 NumPy 快了 N 个数量级。需要注意,JAX 使用的是 TPU,NumPy 使用了 CPU,以此强调 JAX 的速度上限远高于 NumPy。
作者列出了以下六条可能想要使用 JAX 的理由:
NumPy 加速器。NumPy 是使用 Python 进行科学计算的基础包之一,但它仅与 CPU 兼容。JAX 提供了 NumPy 的实现(具有几乎相同的 API),可以非常轻松地在 GPU 和 TPU 上运行。对于许多用户而言,仅此一项功能就足以证明使用 JAX 的合理性;
XLA。XLA(Accelerated Linear Algebra)是专为线性代数设计的全程序优化编译器。JAX 建立在 XLA 之上,显著提高了计算速度上限;
JIT。JAX 允许用户使用 XLA 将自己的函数转换为即时编译(JIT)版本。这意味着可以通过在计算函数中添加一个简单的函数装饰器(decorator)来将计算速度提高几个数量级;
Auto-differentiation。JAX 将 Autograd(自动区分原生 Python 代码和 NumPy 代码)和 XLA 结合在一起,它的自动微分能力在科学计算的许多领域都至关重要。JAX 提供了几个强大的自动微分工具;
深度学习。虽然 JAX 本身不是深度学习框架,但它的确为深度学习提供了一个很好的基础。很多构建在 JAX 之上的库旨在提供深度学习功能,包括 Flax、Haiku 和 Elegy。甚至在最近的一些 PyTorch 与 TensorFlow 文章中强调了 JAX 作为一个值得关注的「框架」,并推荐其用于基于 TPU 的深度学习研究。JAX 对 Hessians 的高效计算也与深度学习相关,因为它们使高阶优化技术更加可行;
通用可微分编程范式(General Differentiable Programming Paradigm )。虽然我们可以使用 JAX 来构建和训练深度学习模型,但它也为通用可微编程提供了一个框架。这意味着 JAX 可以通过使用基于模型的机器学习方法来解决问题,从而可以利用数十年研究建立起的给定领域的先验知识。
JAX 转换
到目前为止,我们已经讨论了 XLA 以及它如何允许 JAX 在加速器上实现 NumPy;但请记住,这只是 JAX 定义的一半。JAX 不仅为强大的科学计算提供了工具,而且还为可组合的函数转换提供了工具。
举例来说如果我们对标量值函数 f(x) 使用梯度函数转换,那么我们将得到一个向量值函数 f'(x),它给出了函数在 f(x) 域中任意点的梯度。
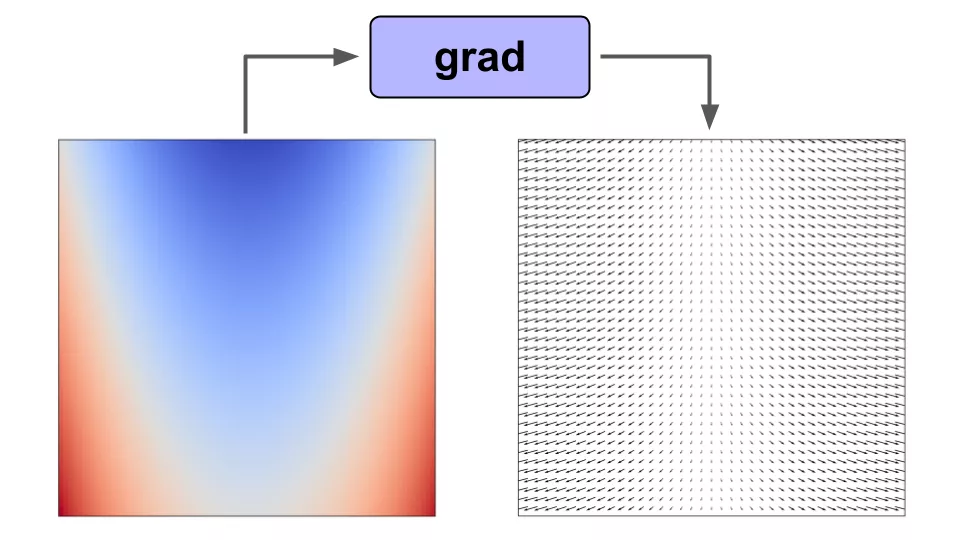 在函数上使用 grad() 可以让我们得到域中任意点的梯度
在函数上使用 grad() 可以让我们得到域中任意点的梯度
JAX 包含了一个可扩展系统来实现这样的函数转换,有四种典型方式:
Grad() 进行自动微分;
Vmap() 自动向量化;
Pmap() 并行化计算;
Jit() 将函数转换为即时编译版本。
使用 grad() 进行自动微分
训练机器学习模型需要反向传播。在 JAX 中,就像在 Autograd 中一样,用户可以使用 grad() 函数来计算梯度。
举例来说,如下是对函数 f(x) = abs(x^3) 求导。我们可以看到,当求 x=2 和 x=-3 处的函数及其导数时,我们得到了预期的结果。
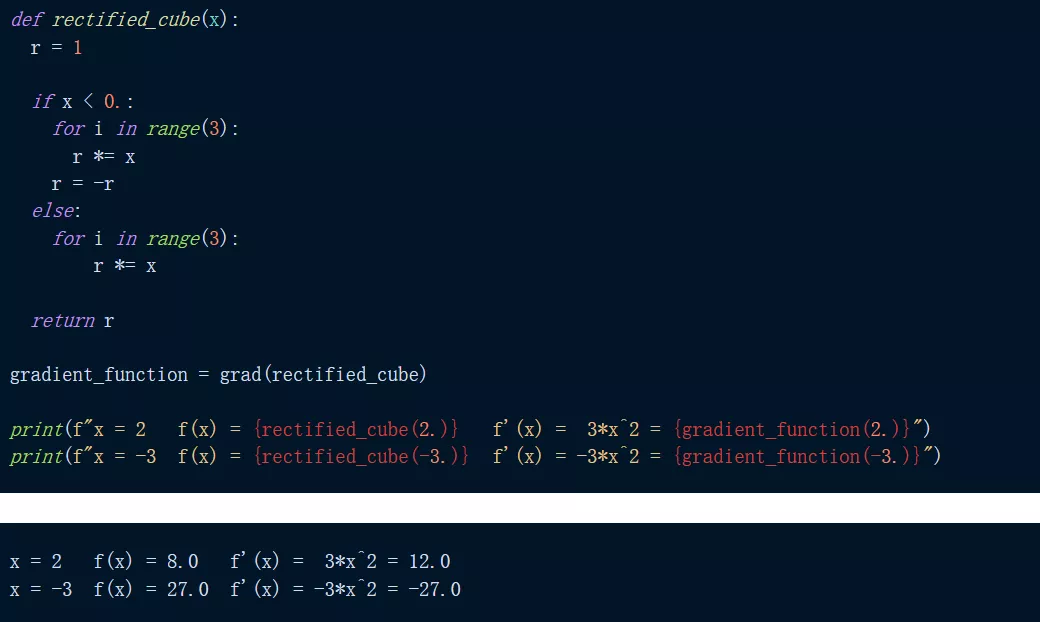
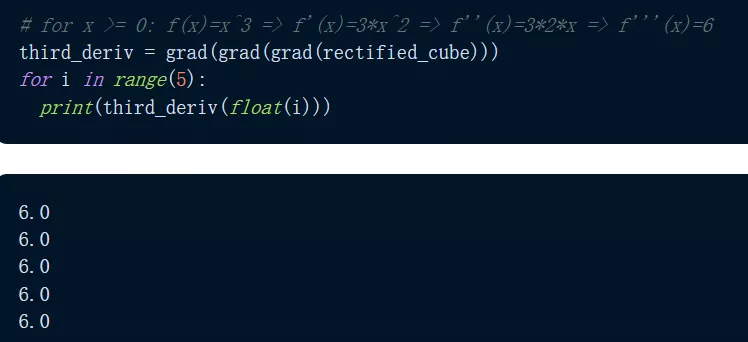
那么 grad() 能微分到什么程度?JAX 通过重复应用 grad() 使得微分变得很容易,如下程序我们可以看到,输出函数的三阶导数给出了 f'''(x)=6 的恒定预期输出。
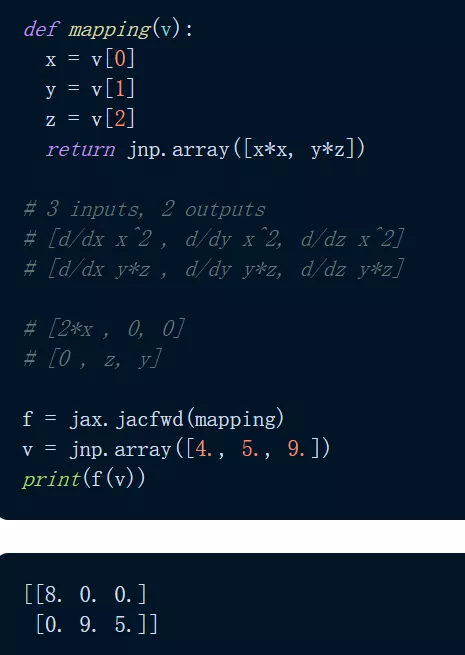
可能有人会问,grad() 可以用在哪些方面?标量值函数:grad() 采用标量值函数的梯度,将标量 / 向量映射到标量函数。此外还有向量值函数:对于将向量映射到向量的向量值函数,梯度的类似物是雅可比矩阵。使用 jacfwd() 和 jacrev(),JAX 返回一个函数,该函数在域中的某个点求值时产生雅可比矩阵。
从深度学习角度来看,JAX 使得计算 Hessians 变得非常简单和高效。由于 XLA,JAX 可以比 PyTorch 更快地计算 Hessians,这使得实现诸如 AdaHessian 这样的高阶优化更加快速。
下面代码是在 PyTorch 中对一个简单的输入总和进行 Hessian:
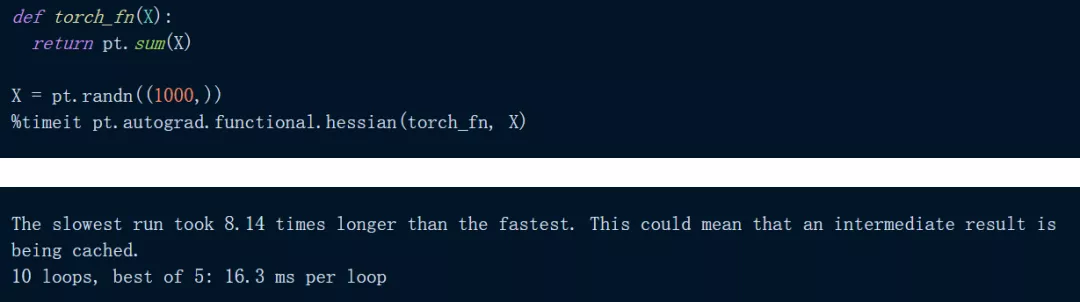 正如我们所看到的,上述计算大约需要 16.3 ms,在 JAX 中尝试相同的计算:
正如我们所看到的,上述计算大约需要 16.3 ms,在 JAX 中尝试相同的计算:
使用 JAX,计算仅需 1.55 毫秒,比 PyTorch 快 10 倍以上: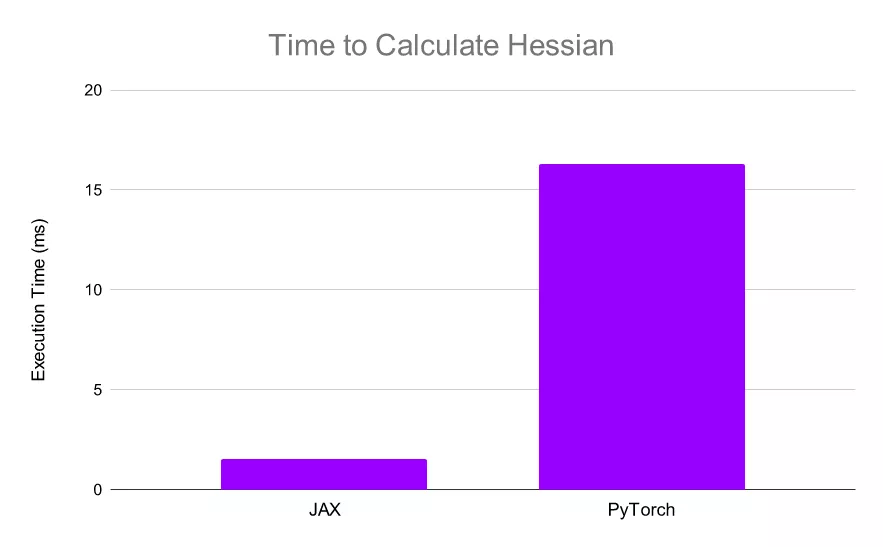 JAX 可以非常快速地计算 Hessians,使得高阶优化更加可行。
JAX 可以非常快速地计算 Hessians,使得高阶优化更加可行。
使用 vmap() 自动向量化
JAX 在其 API 中还有另一种变换:vmap() 自动向量化。以下是矢量化向量加法展示:
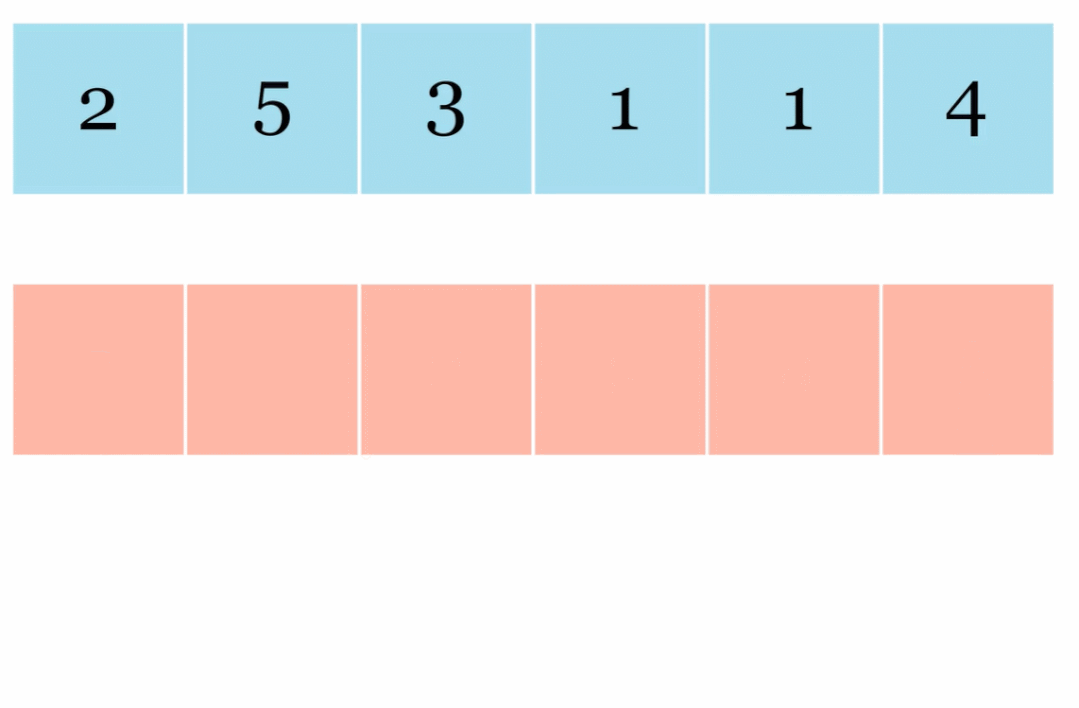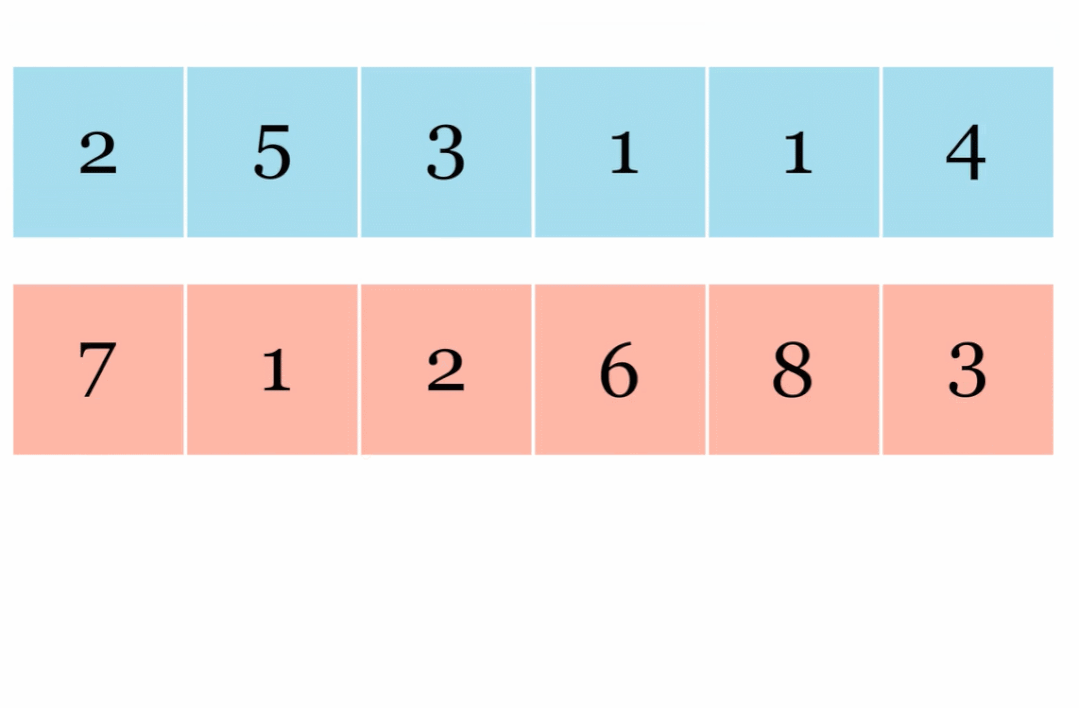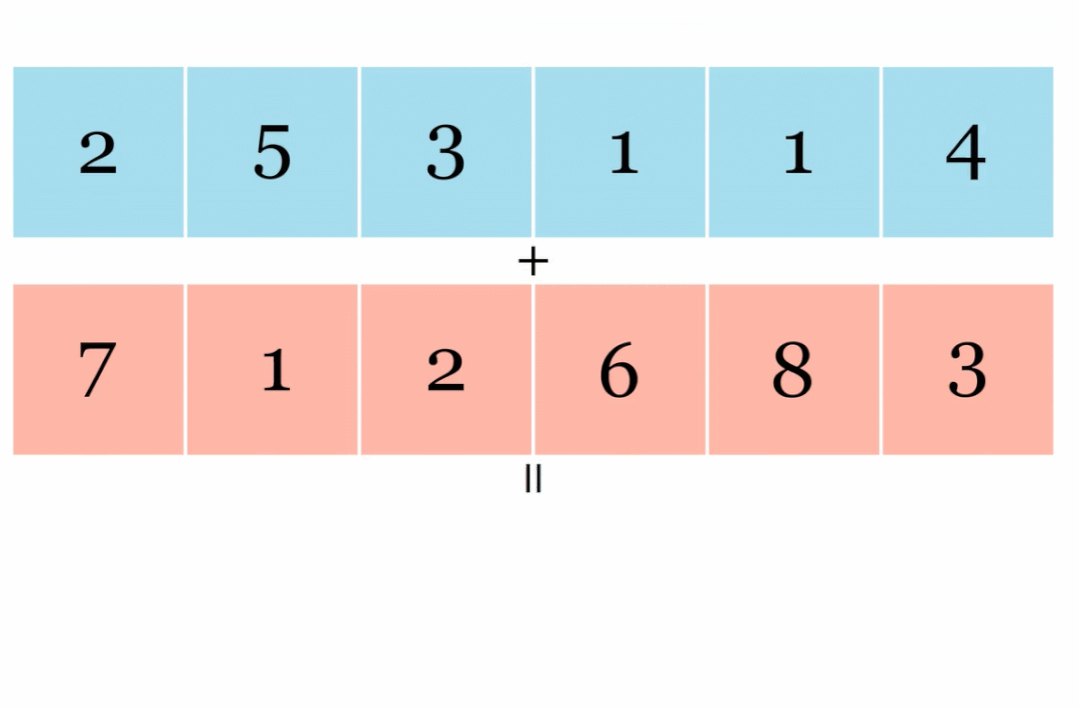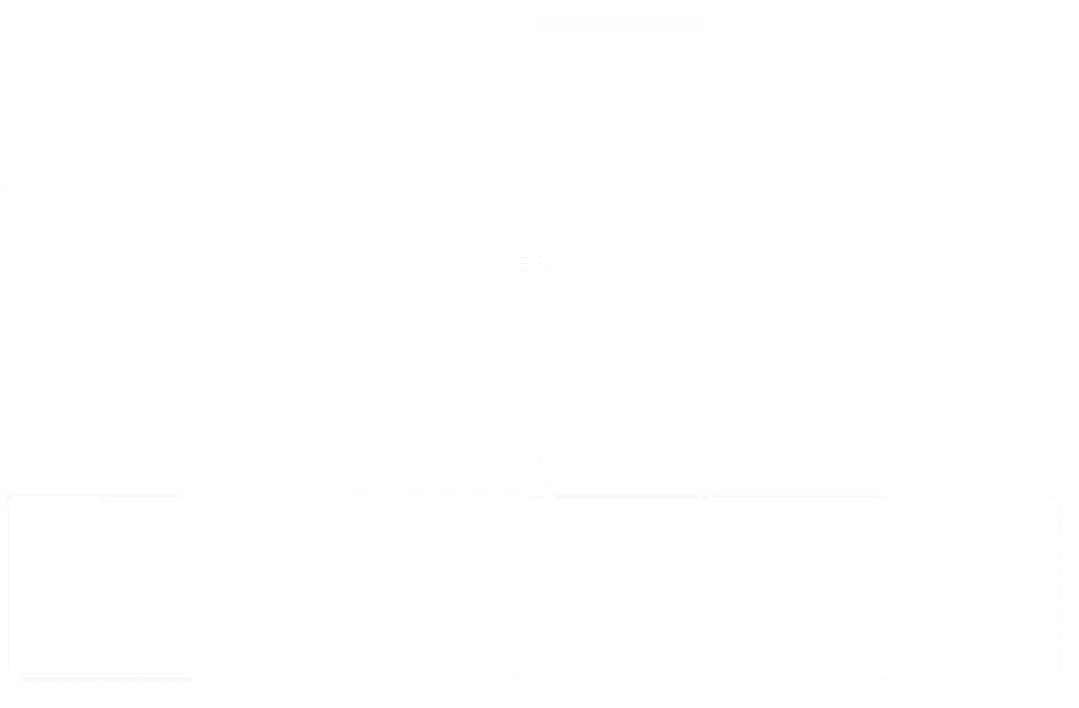
使用 pmap() 实现自动并行化
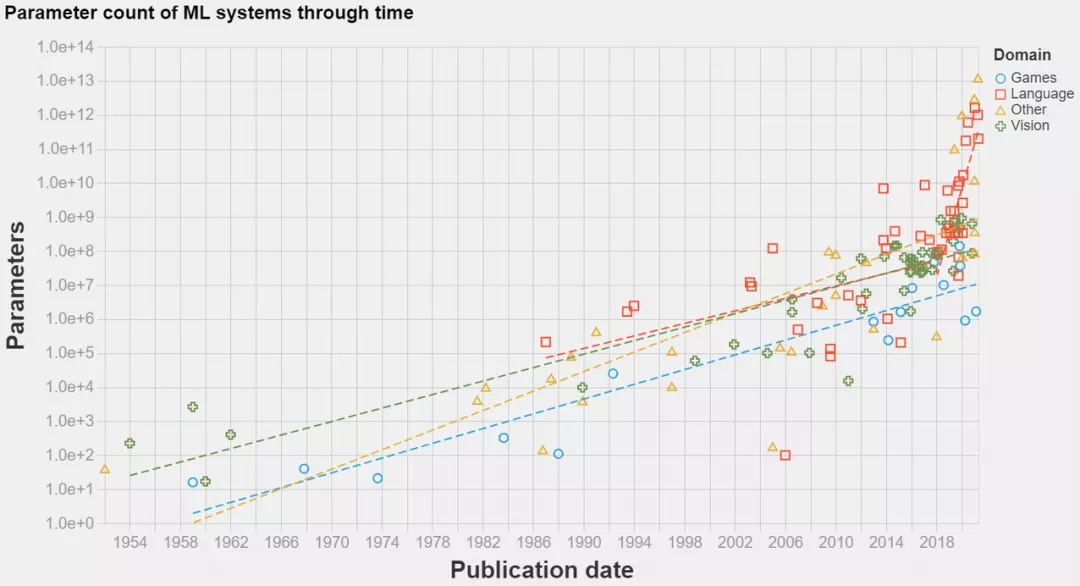
分布式计算变得越来越重要,在深度学习中尤其如此,如下图所示,SOTA 模型已经发展到超大规模。
得益于 XLA,JAX 可以轻松地在加速器上进行计算,但 JAX 也可以轻松地使用多个加速器进行计算,即使用单个命令 - pmap() 执行 SPMD 程序的分布式训练。
我们以向量矩阵乘法为例,如下为非并行向量矩阵乘法:
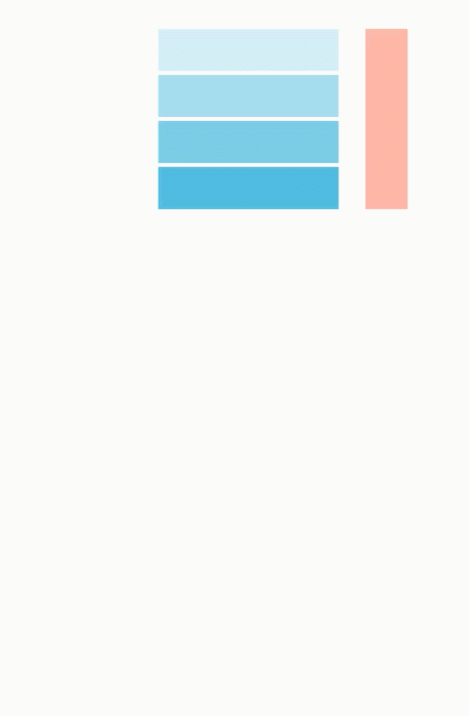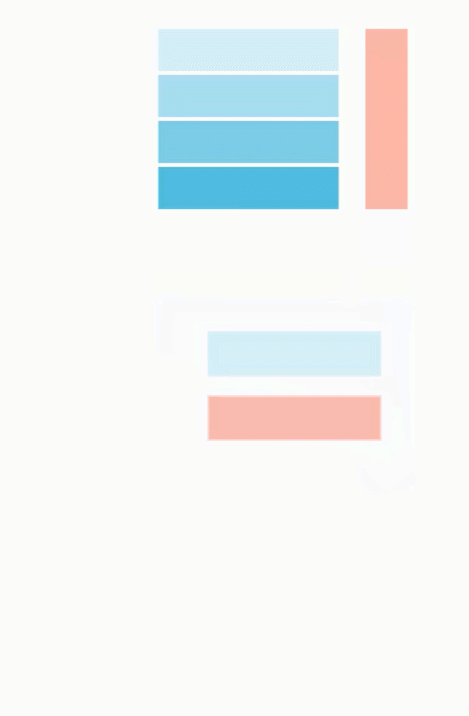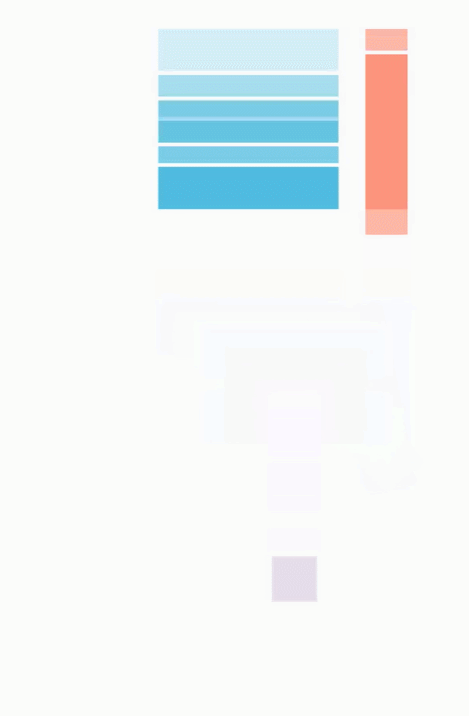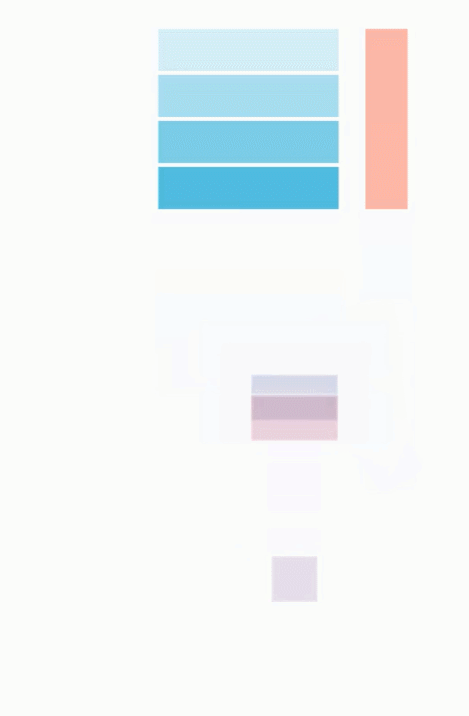
使用 JAX,我们可以轻松地将这些计算分布在 4 个 TPU 上,只需将操作包装在 pmap() 中即可。这允许用户在每个 TPU 上同时执行一个点积,显着提高了计算速度(对于大型计算而言)。

使用 jit() 加快功能
JIT 编译是一种执行代码的方法,介于解释(interpretation)和 AoT(ahead-of-time)编译之间。重要的是,JIT 编译器在运行时将代码编译成快速的可执行文件,但代价是首次运行速度较慢。
JIT 不是一次将一个操作分配给 GPU 内核,而是使用 XLA 将一系列操作编译成一个内核,从而为函数提供端到端编译的高效 XLA 实现。
以下图为例,代码定义了一个函数:用三种方式计算 5000 x 5000 矩阵——一次使用 NumPy,一次使用 JAX,还有一次在 JIT 编译的函数版本上使用 JAX。我们首先在 CPU 上进行实验:
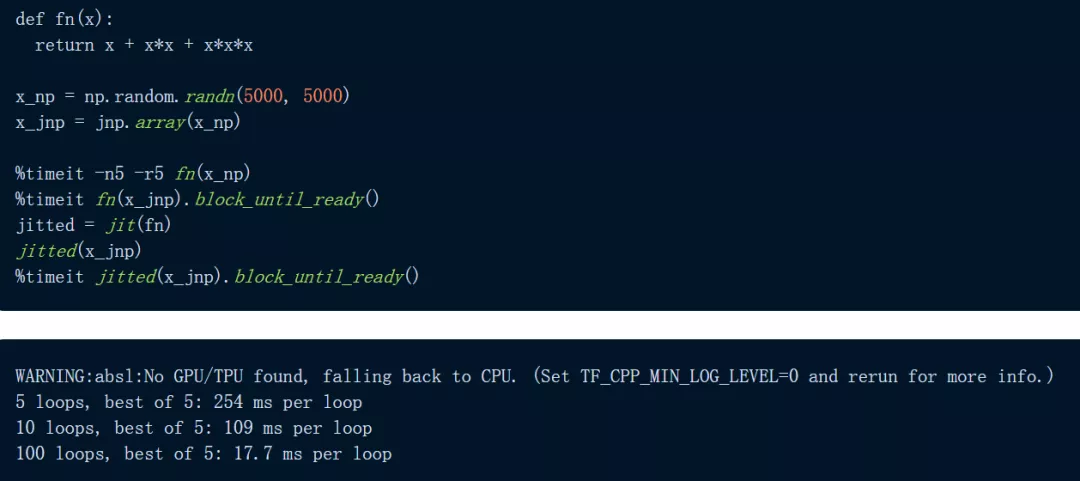
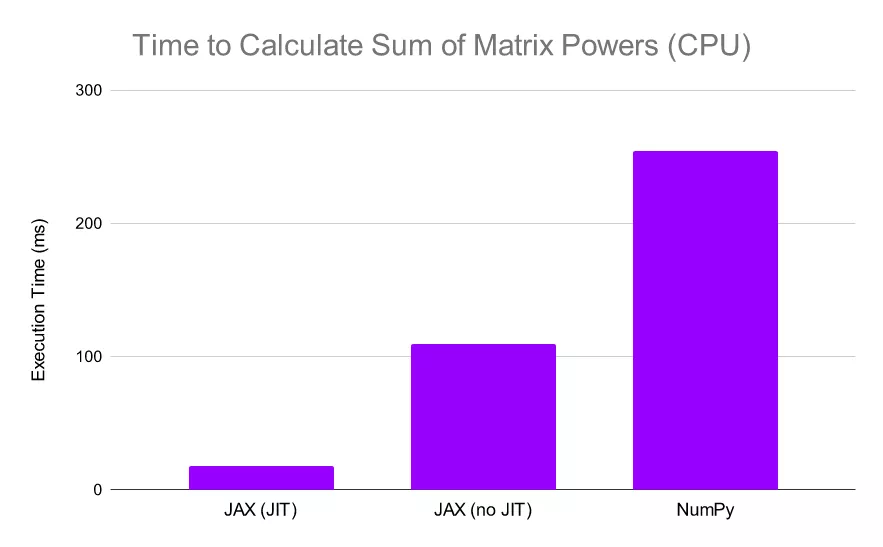 JAX 对于逐元素计算明显更快,尤其是在使用 jit 时。
JAX 对于逐元素计算明显更快,尤其是在使用 jit 时。
我们看到 JAX 比 NumPy 快 2.3 倍以上,当我们 JIT 函数时,JAX 比 NumPy 快 30 倍。这些结果已经令人印象深刻,但让我们继续看,让 JAX 在 TPU 上进行计算:
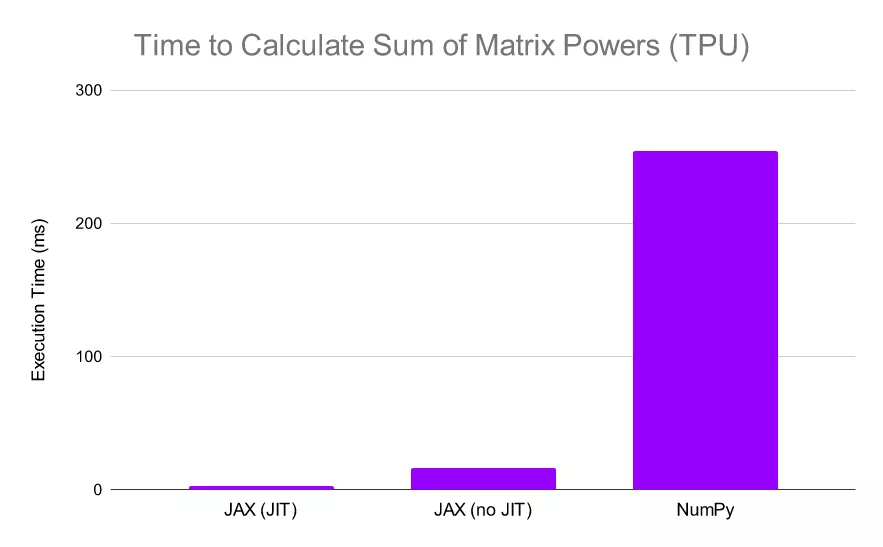
当 JAX 在 TPU 上执行相同的计算时,它的相对性能会进一步提升(NumPy 计算仍在 CPU 上执行,因为它不支持 TPU 计算)在这种情况下,我们可以看到 JAX 比 NumPy 快了惊人的 13 倍,如果我们同时在 TPU 上 JIT 函数和计算,我们会发现 JAX 比 NumPy 快 80 倍。
当然,这种速度的大幅提升是有代价的。JAX 对 JIT 允许的函数进行了限制,尽管通常允许仅涉及上述 NumPy 操作的函数。此外,通过 Python 控制流进行 JIT 处理存在一些限制,因此在编写函数时须牢记这一点。
2022 年了,我该用 JAX 吗?
很遗憾,这个问题的答案还是「视情况而定」。是否迁移到 JAX 取决于你的情况和目标。为具体分析是否应该(或不应该)在 2022 年使用 JAX,这里将建议汇总到下面的流程图中,并针对不同的兴趣领域提供不同的图表。
科学计算
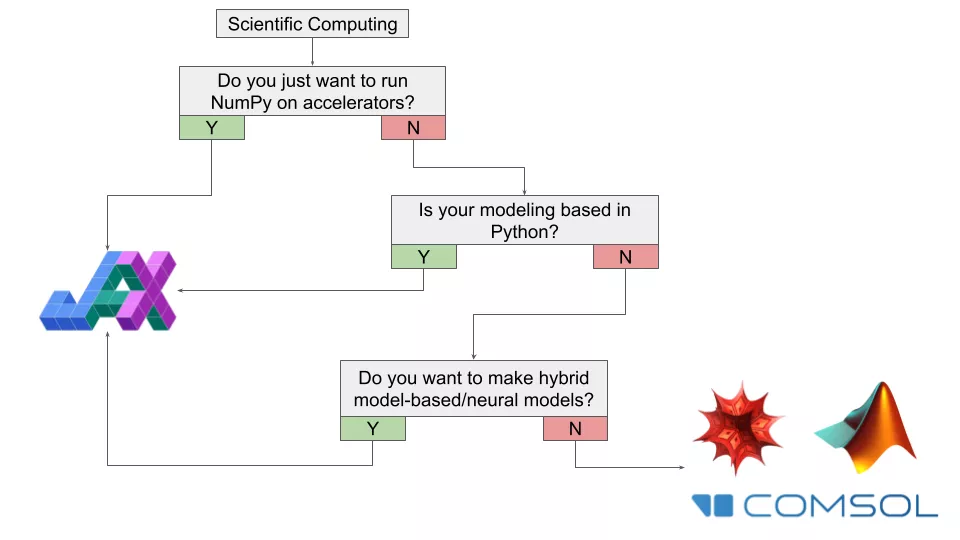
如果你对 JAX 在通用计算感兴趣,首先要问的问题就是——是否只尝试在加速器上运行 NumPy?如果答案是肯定的,那么你显然应该开始迁移到 JAX。
如果你不只处理数字而是参与动态计算建模,那么是否应该使用 JAX 将取决于具体用例。如果大部分工作是在 Python 中使用大量自定义代码完成的,那么开始学习 JAX 以增强工作流程是值得的。
如果大部分工作不在 Python 中,但你想构建的是某种基于模型 / 神经网络的混合系统,那么使用 JAX 可能是值得的。
如果大部分工作不使用 Python,或者你正在使用一些专门的软件进行研究(热力学、半导体等),那么 JAX 可能是不合适的工具,除非你想从这些程序中导出数据,用来做自定义计算。如果你感兴趣的领域更接近物理 / 数学并包含计算方法(动力系统、微分几何、统计物理)并且大部分工作都在例如 Mathematica 上,那么坚持使用目前的工具才是值得的,特别是在已有大型自定义代码库的情形下。
深度学习
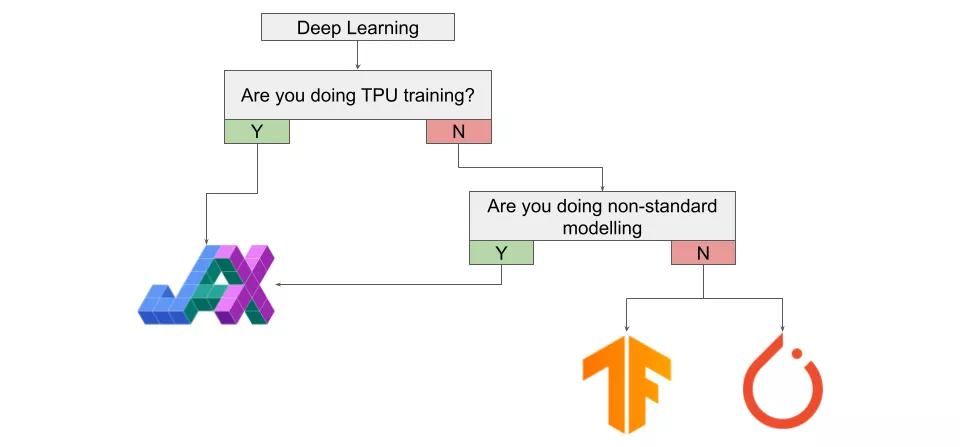
虽然我们已经强调过,JAX 不是专为深度学习构建的通用框架,但 JAX 速度很快且具有自动微分功能,你肯定想知道使用 JAX 进行深度学习是什么样的。
若想在 TPU 上进行训练,那么你应该开始使用 JAX,尤其是如果当前正在使用的是 PyTorch。虽然有 PyTorch-XLA 存在,但使用 JAX 进行 TPU 训练绝对是更好的体验。如果你正在研究的是「非标准」架构 / 建模,例如 SDE-Nets,那么也绝对应该尝试一下 JAX。此外,如果你想利用高阶优化技术,JAX 也是要尝试的东西。
如果你不是在构建特殊的架构,只是在 GPU 上训练常见的架构,那么你现在可能应该坚持使用 PyTorch 或 TensorFlow。然而,这个建议可能会在未来一两年内快速发生变化。虽然 PyTorch 仍然在研究领域占据主导地位,但使用 JAX 的论文数量一直在稳步增长。随着 DeepMind 和谷歌重量级玩家不断开发用于 JAX 的高级深度学习 API,在几年内 JAX 可能会出现爆炸性的增长率。
这意味着你至少应该稍微熟悉一下 JAX,如果你是研究人员的话更应如此。
深度学习初学者
但如果我只是个初学者呢?情况会有些不一样。
如果你有兴趣了解深度学习并实现一些想法,你应该使用 JAX 或 PyTorch。如果你想自上而下学习深度学习,或有一些 Python 软件的经验,则应该从 PyTorch 入手。如果你想自下而上地学习深度学习,或具有数学背景,你可能会发现 JAX 很直观。在这种情况下,在进行任何大型项目之前,请确保了解如何使用 JAX。
如果你对深度学习感兴趣,又想转行相关的职位,那么你需要使用 PyTorch 或 TensorFlow。尽管最好是同时熟悉两个框架,但你必须知道 TensorFlow 被普遍认为是「行业」框架,不同框架的职位发布数量证明了这一点: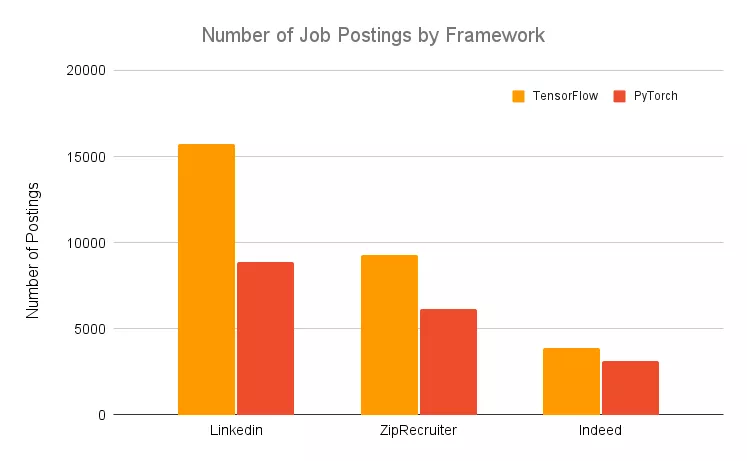
如果你是一个没有数学或软件背景但想学习深度学习的初学者,那么你不会想使用 JAX。相反,Keras 是更好的选择。
不该使用 JAX 的四条理由
虽然上文已经讨论了很多 JAX 的正面反馈,它有潜力极大地提升用户程序的性能。但作者同时列举了以下四条不该使用 JAX 的理由:
JAX 仍然被官方认为是一个实验性框架。JAX 是一个相对「年轻」的项目。目前,JAX 仍被视为一个研究项目,而不是成熟的谷歌产品,因此如果用户正在考虑迁移到 JAX,请记住这一点;
使用 JAX 一定要勤勉。调试的时间成本,或者更严重的是,未跟踪副作用(untracked side effects)的风险可能导致那些没有扎实掌握函数式编程的用户不适用 JAX。在开始将它用于正式项目之前,请确保自己了解使用 JAX 的常见缺陷;
JAX 没有针对 CPU 计算进行优化。鉴于 JAX 是以「加速器优先」的方式开发的,因此每个操作的分派并未针对 JAX 进行完全优化。在某些情况下,NumPy 实际上可能比 JAX 更快,尤其是对于小型程序而言,这是因为 JAX 引入了开销;
JAX 与 Windows 不兼容。目前在 Windows 上不支持 JAX。如果用户使用 Windows 系统但仍想尝试 JAX,可以使用 Colab 或将其安装在虚拟机(VM)上。

