在过去几年里,机器翻译领域发生了一场革命。利用深度学习构建的新翻译系统取代了语言学家利用统计学领域几十年的研究成果构建的旧系统。像 Google Translate 这样的热门翻译产品,已经将其内部结构换掉,用新的深度学习模型取代了旧的代码。

这对大家来说,是极好的。深度学习的方法不仅更准确,而且你不必拥有语言学研究生学历就能理解。从理论上讲,它很简单,只要有足够的训练数据和算力,谁都可以构建自己的语言翻译系统。话虽如此,但要自己开发一个翻译系统还是有一定的难度,因为对于一般的玩票来说,所需的数据量和算力让人望而却步。
但就像机器学习中的其他东西一样,机器翻译也在迅速成熟。工具越来越容易使用,GPU 也越来越强大,训练数据比以往任何时候都要丰富得多。现在,你可以使用现成的硬件和软件来构建语言翻译系统了,这些硬件和软件都已经足够好,足以用于实际项目了。最棒的是,你无需向 Google 支付任何 API 费用,就可以使用它。
那就让我们开始吧!让我们构建一个西班牙语到英语的翻译系统,可以准确地将包含未列入词汇表中的词汇的文本进行翻译。
基于神经网络的文本翻译
我们这个翻译系统的核心将是一个神经网络,它接受一条句子并输出该句子的翻译结果。我以前写过关于机器翻译系统的历史,以及我们如何使用神经网络来翻译文本,下面是简短版本:
神经翻译系统实际上是两个神经网络连接在一起,端到端的神经网络。第一个神经网络学习将单词序列(即句子)编码成代表其意义的数字数组。第二个神经网络学会将这些数字解码成一系列意思相同的单词。诀窍是,编码器接受一种语言的单词,但解码器输出的是另一种语言的单词。因此,实际上该模型通过中间的数字编码,来学习一种人类语言到另一种语言的映射。
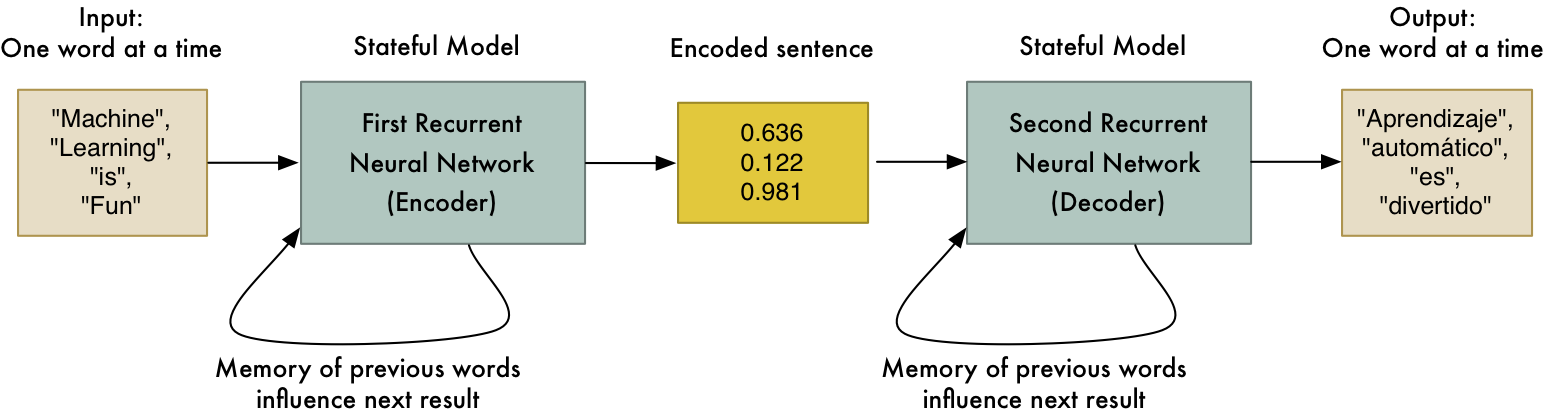
为了对句子的意思进行编码和解码,我们将使用一种特殊类型的神经网络,称为递归神经网络。一个标准的神经网络是没有记忆的。如果你给它同样的输入,它每次都会得出同样的结果。相比之下,递归神经网络之所以被称为递归,是因为上一次的输入会影响下一次的预测。
这很有用,因为句子中的每个单词都不是独立存在的。每个单词的意思要取决于它在句子中的上下文。通过让句子中的每个单词影响下一个单词的值,可以让我们捕获到上下文的一些内容。
因此,如果你向神经网络显示单词 “My”、“name”、“is”,然后要求它对 “Adam” 这个词的含义进行编码,它就会用前面的词来知道表示 “Adam” 这个词作为名字的意思。如果你想了解更多有关其工作原理的细节,请查看我之前写的文章。
如果你非常精通机器学习,那么,一提到递归神经网络,你可能会打哈欠。如果是这样,请跳到下面的 Linux shell 命令,开始训练你的模型吧。我知道,机器学习是一个发展迅速的领域,几年前绝对是革命性的东西,搁到现在已经成了古老的事物。
事实上,还有一种更新颖的语言翻译方法,它使用了一种叫做 Transformer 的新型模型。Transformer 模型更进一步,通过对每一个单词之间的交叉关系进行建模,而不是仅仅考虑单词的顺序,试图捕获句子中每个单词的上下文意义。我也写过关于 Transformer 模型的文章,但为了保持合理的训练时间,我们将在这个项目中使用递归神经网络。别担心,效果还是会很好的!
完整的翻译管道
很好,我们将使用两个递归神经网络来翻译文本。我们将训练第一个神经网络对西班牙语的句子进行编码,然后训练第二个神经网络将其解码为英语。如果你相信我在 reddit 上的评论,那么每个已安装 Python 的高中生都已经知道如何创建一个递归神经网络了。所以,是时候开始了,对吧?
别这么快!我们还需要一种策略,来处理凌乱的真实数据。人类非常擅长在没有任何帮助的情况下从混乱的数据中提取信息。例如,你可以毫不费力地读下面这句话:
cOMPuTERs are BAd at UNderStandING Messy DAtA…
一个用格式完美的文本进行训练的神经网络根本不会知道这句话是什么意思。神经网络并没有能力在训练数据之外进行推断。如果神经网络之前没有见过 “cOMPuTERs” 这个词,它不会自动地知道这个词跟 “computers” 的意思是一样的。
解决方案是将文本进行归一化,我们希望消除尽可能多的格式变化。我们将确保单词在相同的上下文总是以相同的方式大写,我们将修复标点符号前后的任何奇怪的格式,并清理 MS Word 软件随机添加的任何奇怪的引号,等等。整个想法就是,无论用户如何输入,都会确保相同的句子总是以完全相同的方式输入。
下面是文本归一化的一个示例:
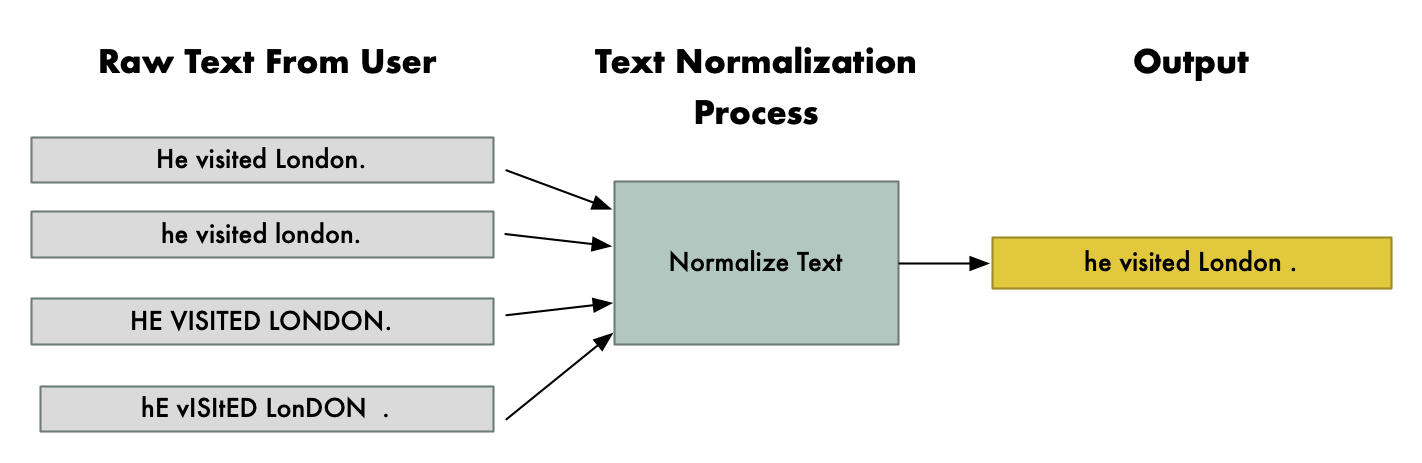
请注意,无论用户的 Shift 键用得多糟糕,“He visited London”这句话是如何以同样的方式进行归一化的。注意,“London”总是大写,而其他单词没有大写,因为它通常被用作专用名词。确保文本格式清晰,会让神经网络的工作变得轻松很多。
下面是我们完整的翻译流程,用我们想要翻译的文本说明,用翻译后的版本来结束:

首先,我们需要将文本分割成句子。我们的神经网络每次只能翻译一个句子,如果我们试图一次性把整段的句子馈入,效果会很差。
将文本分割成句子看起来似乎很容易,但实际上是一个棘手的任务,因为有人可以用各种不同的方式来嵌套标点和格式。在这个项目中,我们将使用一个用 Python 编写的简单的句子分割器来减少你需要安装的第三方库。但是 NLP 库 (如 spaCy ) 包含了复杂的句子分割模型,如果还不能满足你的需求,你就可以使用这些模型。
接下来,我们将对文本进行归一化处理。这是最难的部分,如果你在这一步上偷工减料的话,最终的结果会很难看的。而一旦我们将文本成功归一化后,就可以将它馈入到翻译模型中了。
记住,你还需要反转文本归一化和句子分割步骤来生成最终的翻译。所以,我们会有一个去归一化的步骤,然后再把文本重新组合成句子的步骤。
软件及硬件要求
Python 3
我们将使用 Python 3 编写胶水代码来对文本进行归一化、执行翻译,并输出结果。
Marian NMT(机器翻译深度学习框架)
你可能以为我们会使用像 TensorFlow 或 PyTorch 之类的通用机器学习框架来实现我们的翻译模型。取而代之的是,我们使用 Marian NMT,这是一个基于 C++ 的机器学习框架,专门为机器翻译而设计,主要由 Microsoft Translator 团队开发。它已经内置了多个神经翻译模型架构。
虽然 TensorFlow 和 PyTorch 非常适合用来实验或尝试新的神经网络设计。但是,一旦你搞清楚了模型架构,并试图扩展你的设计来处理真实世界的用户,你就可以不再需要通用工具了。
Marian NMT 是一种专用工具,旨在让你能够轻松地快速构建生产级翻译系统。你没有必要“重新发明轮子”。这是一个例子,说明随着机器学习从研究实验室进入日常使用,软件是如何变得更加成熟的。
带有 GPU 的台式计算机
要运行 Marian,我们需要一台 Linux 计算机。任何一台计算机都可以,只能性能足够强,应该都可以运行。我使用的是一台台式机计算机,装的是 Ubuntu Linux 18.04,配置了 Intel i7 处理器和 32GB 内存。为了存储训练数据,我使用的是普通的 SSD 硬盘。
重要的是,计算机要有一个好的 NVIDIA GPU,还要有足够的显存。GPU 要承担大部分的计算工作,所以 GPU 就是你应该投资的地方。我使用的是 NVIDIA TITAN RTX,显存为 24GB。至少,你需要一个最低 8GB 显存的 GPU。至于其他不错的消费级 GPU,如 GTX 1080 Ti 或 GTX 2080 Ti 是可以用的;像 NVIDIA TESLA 或 Quadro 系列这样服务器级的 GPU 也是可以的。
你可以将 Marian 与单个 GPU 或多个 GPU 并行使用来加快速度,但每个 GPU 都需要有足够的内存来单独保存模型和训练数据。也就是说,两个 4GB 显存的 GPU 并不能代替一个 8GB 显存的 GPU 工作。
准备你的计算机
安装 Ubuntu Linux 18.04 LTS
尽管得到了 Microsoft 的支持,但 Marian 尚无法在 Windows 上运行。而且也不能在 Mac OS 上运行。所以,你要么在你的计算机上安装 Linux,要么考虑从你最喜欢的云服务提供商哪里租用一台云端中的 Linux 机器。
我建议,为这个项目安装 Ubuntu Linux 18.04 LTS。尽管最近发布了 Ubuntu Linux 20.04 LTS,但是 GPU 驱动程序和深度学习库都需要时间来更新以适应新版本的 Ubuntu。所以,千万不要尝试使用最新版本的 Ubuntu,除非你愿意面对额外的、令人头疼的问题,并自己解决安装问题。
安装 NVIDIA 的 CUDA 和 cuDNN 库
NVIDIA 的 CUDA 和 cuDNN 库可以让 Marian 利用你的 GPU 来加速训练过程。因此,在我们继续之前,如果你还没有安装 CUDA 和 cuDNN 的话,请先安装这些。
在 Ubuntu Linux 18.04 上,我建议安装 CUDA/cuDNN 版本 10.1,这些版本适用于 Marian。
如果你安装了不同的版本,就必须调整下面的命令来匹配。NVIDIA 因为在 CUDA 的新版本中做了一些微小的改动而臭名昭著,这些改动会导致旧版本软件出现不兼容性。因此,如果你偏离了标准路径,请再次做好自己调试的准备。
安装 Marian 和训练脚本
在编译 Marian 之前,你需要安装比 Ubuntu 18.04 默认包含的更新版本的 CMake。你还需要安装一些其他必备条件。
不过,你不用担心,这没什么大不了的,你只需运行下面终端命令即可:
复制代码
# Install newer CMake via 3rd-party repowget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null |sudo apt-key add -sudo apt-add-repository 'deb https://apt.kitware.com/ubuntu/ bionic main'sudo apt-get install cmake git build-essential libboost-all-dev
请注意,这些命令将从第三方软件包仓库中拉取软件包。因此,请检查命令正在执行的操作,以确保没有问题。
安装了这些必备条件后,运行以下命令并编译 Marian(包括示例和助手工具,它们分布在不同的 git repo 中):
复制代码
# Download and compile Mariancd ~git clone https://github.com/marian-nmt/mariancd marianmkdir buildcd buildcmake -DCOMPILE_SERVER=on -DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-10.1/ ..make -j4# Grab and compile the Marian model examples and helper toolscd ~/marian/git clone https://github.com/marian-nmt/marian-examples.gitcd marian-examples/cd tools/make
最后,我分享了我们用 Marian 训练西班牙语到英语模型的脚本。这些脚本是基于 Marian 附带的罗马尼亚语翻译示例,但针对西班牙语到英语进行了修改,并将其扩展到更大的数据集。
复制代码
# Download the Spanish-to-English scripts for this articlecd ~/marian/marian-examplesgit clone https://github.com/ageitgey/spanish-to-english-translation# Install the Python modules we'll use latercd spanish-to-english-translationsudo python3 -m pip install -r requirements.txt
你可以自由地调整这些脚本,使其适用于你想要翻译的任何语言对。像法语或意大利语这样的基于拉丁语的语言几乎不需要什么修改;而像普通话这样的不太相似的语言就需要更多的工作了。
怎样找到训练数据
要训练一个翻译模型,我们需要数百万对完全相同的句子,只是它们已经被翻译成两种语言,这就是所谓的平行语料库(parallel corpora)。
我们拥有的句子对越多,模型就能更好地学习如何翻译不同类型的文本。要创建工业级强度的模型,就需要数千万个训练句子,甚至更多。而且最重要的是,这些句子需要覆盖整个人类表达的所有方面,从正式文件到俚语和笑话。
糟糕的翻译系统和像 Google Translate 这样强大的翻译系统之间最大的区别在于:训练数据的数量和种类!幸运的是,在 2020 年,我们可以在很多地方找到偶然创建的并行数据,并可以通过一些巧妙的技巧将其转换成训练句子对。
对于正式文件和法律文本,我们有来自欧盟的礼物。它们将其法律文件翻译成成员国的所有语言,其中就包括了英语和西班牙语。沿着同样的思路,我们可以从其他国际机构找到交叉翻译的法律文本,如联合国和欧洲央行。
对于历史写作,我们可以从已经被翻译成不同语言的经典书籍中找到句子对。我们可以拿没有版权的书籍,将这些作品的不同译本进行配对,以创造句子对,我们知道这些句子对说的是同一件事。
对于非正式的谈话,我们有 DVD 的礼物。自 20 世纪 90 年代末推出 DVD 格式以来,几乎所有的电影和电视节目都包含了多种语言的字幕,这些字幕机器可读。我们可以对同一部电影和电视节目的不同翻译进行配对,以创建并行数据。同样的想法也适用于带有字幕的新内容,比如蓝光和 YouTube 视频。
现在,我们知道在哪里可以找到这些数据了,但要把这些数据全部清理并准备好,还是有很多工作要做的。幸运的是,开放平行语料库(Open Parallel Corpus,OPUS)的那些人已经完成了收集多种语言的句子对工作,这些人非常了不起。你可以在他们的网站上浏览并下载他们所有的平行句子数据。这将大大加快我们的项目,所以请务必在本文文末查看他们工作的引文。
我们稍后将运行的训练脚本将自动从 OPUS 下载这些数据源,这为我们提供了近 8500 万个翻译过的句子对,而且不需要任何工作。这太棒了!
OPUS 按语言对提供文件。因此,如果你想创建一个比如说芬兰语到意大利语的翻译模型,而不是西班牙语到英语,你可以通过下载该语言对的文件来实现。请记住,对于使用不太广泛的语言,是很难找到句子对的。另外,还请记住,有些语言需要独特的文本归一化方法,而本文的这个例子中并没有涉及到这些方法。
同时请注意,这些数据来自不同的地方,质量良莠不齐。这些下载中肯定会存在一些错误或重复的数据。当你使用庞大的数据集时,数据质量将永远得不到保证,并且,你还需要经常亲自动手来发现和修复任何明显的问题。
合并和准备训练数据
我提供的用于训练模型的脚本会自动为你下载并准备数据,但如果你要为其他语言对构建翻译模型,还是有必要讨论一下所涉及的步骤。
我们从 OPUS 下载的每个数据源都会包含两个文本文件。一个文本文件有一个英语句子列表,另一个文本文件有一个与之相配的西班牙语句子列表,顺序相同。因此,我们最终会有许多文本文件,如下图所示。
我们需要经过几个步骤来准备训练数据:
合并:将所有英语文本合并成一个大型文本文件。同样地,将所有的西班牙语文件合并起来,确保保持所有的句子顺序,以便英语和西班牙语文件仍然相配。
随机洗牌:将每个文件中句子的顺序进行随机洗牌(Shuffle),同时保持英语和西班牙语中句子的相对顺序相同。将不同来源的训练数据混合在一起,可以帮助模型学习在不同类型的文本中进行泛化,而不是先学习翻译正式数据,然后在学习翻译非正式数据,以此类推。
分割:将煤种语言的主数据文件分割成训练、开发和测试部分。我们将根据大量的训练数据对模型进行训练,但保留一些句子来测试模型并确保其工作正常。这就确保了我们测试模型时使用的句子是它在训练中从未见过的,因此我们可以确定它不只是记住了正确的答案。
用子词分割处理生僻新词
训练数据永远不可能覆盖所有可能的单词,因为人们无时无刻不在编造新的单词。为了帮助我们的翻译系统处理从未见过的单词,我们可以使用一种叫做子词分割(Subword Segmentation)的方法。
子词分割就是我们将单词分成更小的片段,并教会模型在每个单词的每个片段之间进行翻译,我们希望的是,如果模型看到一个从未见过的单词,它至少能够通过翻译构成它的子词来猜测这个单词的意思。
想象一下,我们的训练数据中包含了 low、lowest、newer 和 broad 等单词。我们可以将这些词分成词根和后缀(又称词尾,是一种后置于其他词素后的词缀)。
词根:low、new、wid
后缀:est、er
现在想象一下,我们被要求翻译 widest 这个词。即使这个词从来没有出现在训练数据中,但模型会知道如何翻译 wid 和 est,所以通过把这两个子词的翻译放在一起,它就能很好地猜测出 widest 的意思。虽然这并不总是完美的,但它在很多情况下都能很好地工作,这将使翻译模型整体上更加准确。
我们将使用的子词分割的具体实现称为 BPE,即字节对编码(Byte Pair Encoding)。你可以在最初的研究论文了解它的工作原理。
为了利用 BPE 的优势,我们需要训练一个新的 BPE 模型来适应我们的训练数据集,然后在文本归一化过程中加入一个额外的步骤,在这一步骤中,通过 BPE 模型运行文本。同样的,我们还需要在去归一化过程中增加一个步骤,以便重新连接最终翻译中被 BPE 模型分割成单独单词的任何单词。
训练完整的翻译管道
下载训练数据、准备数据、创建 BPE 模型以及与 Marian 一起训练实际翻译模型的整个过程都在一个脚本中完成。要启动所有操作,请运行以下命令:
复制代码
cd ~/marian/marian-examples/spanish-to-english-translation/./run-me.sh
你可以看看 run-me.sh 脚本,看看每一步都发生了什么。脚本写得非常简单明了:它下载训练数据、将其合并,进行归一化,然后启动 Marian 训练过程。
如果要构建一个生产级的翻译系统,你可以随意用自己的实现来替换这个脚本。这个脚本只是起到指导你需要执行哪些步骤的作用。
在数据准备好并且模型开始训练之后,你将会看到如下图所示的输出:
复制代码
[2020-05-01 10:09:23] Ep. 1 : Up. 1000 : Sen. 154,871 : Cost 70.37619781 : Time 370.45s : 5024.86 words/s
下面解释了缩写的含义:
Ep. = Epoch(轮数),指整个训练数据集的通过次数。
Up. = Updates(更新)
Sen. = Sentences(句子)
这条消息是说,我们目前正在进行第一个轮数(即第一次通过训练数据集),到目前为止,模型已经更新了 1000 次,处理了 154871 个句子对。
成本值为 70.3 告诉你模型训练过程中找到最优解决方案的程度。当成本值为 0.0 时,则意味着模型是完美的,能够将任何西班牙语句子转换为训练数据中完美相配的英语翻译。但这永远不会发生,因为模型永远不可能是完美的,而且每个句子也不会只有一个正确的翻译。但是成本值越低,训练过程就越接近于完成。
随着时间的推移,成本值应该会下降,最终,训练将会自动结束。在我的系统中,训练过程大约需要一天的时间,但也有可能需要更长的时间,这取决于你的 GPU 性能和收集的训练数据量。
训练过程中,偶尔会出现暂停,以便在一个小的句子集上验证模型,这些句子不在训练集中。这是为了确保模型在新数据中运行良好,而不仅仅是记忆训练数据。
训练完成后(1~2 天后),所有模型文件都将保存在 /models/ 子文件夹中。这些文件是你在另一个程序中使用翻译模型来翻译新文本所需要的。
我没时间,可以下载你的预训练模型吗?
如果你不想等上一两天训练结束就继续下一个步骤,可以下载我的西班牙语转英语的预训练模型:
复制代码
cd ~/marian/marian-examples/spanish-to-english-translation/wget https://github.com/ageitgey/spanish-to-english-translation/releases/download/0.1/model-spanish-to-english.tar.gztar -zxvf model-spanish-to-english.tar.gz
使用模型翻译新文本
现在进入有趣的部分,让我们试一下我们的新翻译系统!
要翻译文本,我们需要将文本通过与训练数据相同的文本归一化步骤,让神经网络对文本进行翻译,然后再将文本归一化步骤逆向输出。
由于 Marian 模型本身相当大,因此在转换过程中,最慢的步骤之一是将模型加载到内存中。为避免这种延迟,Marian 可以在“服务器模式”下运行,在这种模式下,它保存在内存中,并允许你将其发送翻译请求。我们将使用服务器模式。
要启动 Marian 服务器,请在终端窗口中运行以下命令:
复制代码
cd ~/marian/marian-examples/spanish-to-english-translation/../../build/marian-server --port 8080 -c model/model.npz.best-translation.npz.decoder.yml -d 0 -b 12 -n1 --mini-batch 64 --maxi-batch 10 --maxi-batch-sort src
上述命令是告诉服务器监听端口 8080 上的连接,并使用文件 model.npz.best-translation.npz.decoder.yml 中描述的模型文件。
记住,Marian 服务器只处理我们管道中的翻译步骤,它不进行任何文本归一化步骤。无论如何,都不要犯这个错误:把原始的、未经归一化处理的文本直接发送到 Marian 服务器。如果你这样做的话,会得到很糟糕的结果!我们翻译的新文本需要与训练数据的格式完全相配。这意味着我们需要对翻译的任何新文本应用相同的文本归一化步骤进行处理。
让我们来运行我编写的一个 Python 脚本,它可以翻译一些示例文本。在 Marian 服务器已经运行的情况下,打开一个新的终端窗口并键入如下命令:
复制代码
python3 translate_sentences_example.py
现在,我已经用 Python 代码调用 Marian 包含的相同 Perl 脚本来对训练数据进行归一化处理。这虽然不是超级干净,但它很好用。如果你想把它作为生产系统的一部分来部署,可以用纯 Python 重写这些 Perl 脚本,以避免这些 shell 调用,并加快过程,
Python 脚本中的示例文本是小说《哈利·波特》第一部西班牙语版的第一段。你应该得到这样的输出:
复制代码
Input:El niño que vivió.El señor y la señora Dursley, que vivían en el número 4 de Privet Drive, estaban orgullosos de decir que eran muy normales, afortunadamente.Output:The boy who lived.Mr. and Mrs. Dursley, who lived at number 4 on Privet Drive, were proud to say they were very normal, fortunately.They were the last people who would expect to find themselves related to something strange or mysterious, because they weren't for such nonsense.
注意,如果出现“Connection Refused error”(连接拒绝错误),请检查一下是否启动了 Marian 服务器,并且它仍在另一个终端窗口中运行。
下面是我们翻译的《哈利·波特》与英文原著的对比:

相当不错啊!虽然我们的译文并不完全符合这本小说的英文版本,但它确实传递了同样的意思。如果你看过西班牙语,你会发现我们的翻译的更接近西班牙语的文本。
你可以将脚本中的示例文本替换为你想要翻译的任何内容!现在你已经有了一个可以从 Python 调用的翻译模型,那么,世界就在你的掌握之中。你可以随意地将它包含在你创建的任何其他程序中。以下是一些(或许不怎么样的)想法:
使用 feedparser 库从最喜欢的西班牙报纸中获取 RSS 提要,并自动翻译所有的新闻报道。
编写一个程序来翻译 https://www.meneame.net/ 上的所有文章,这样,你就可以及时了解所有西班牙语最热门的最新动态。
编写一个程序来完成你的西班牙语作业。
祝你玩得开心!
引文
我要感谢这些人,是他们,开发了那么多工具,提供了那么多数据资源,正是因为有了他们的贡献,快速开发一个自己的翻译系统才能成为可能!
Marian:快速神经机器翻译在 C++ 中的实现。 Junczys-Dowmunt、Marcin 和 Grundkiewicz、Roman and Dwojak、Tomasz 和 Hoang、Hieu 和 Heafield、Kenneth 和 Neckermann、Tom 和 Seide、Frank 和 Germann、Ulrich 和 Fikri Aji、Alham 和 Bogoychev、Nikolay 和 Martins、Andre F. T. 和 Birch、Alexandra。2018 年 ACL 会议纪要,系统演示。
http://www.aclweb.org/anthology/P18-4020
OPUS (Open Parallel Corpus,开放平行语料库): Jörg Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
United Nations Corpus(联合国语料库):Ziemski, M.、Junczys-Dowmunt, M. 和 Pouliquen, B.,2016 年,联合国平行语料库、语言资源和评价(LREC '2016), Portorož,斯洛文尼亚,2016 年 5 月。
EMEA(欧洲药品管理局)语料库: http://www.emea.europa.eu/ ,J. Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
ECB(欧洲中央银行)语料库: Alberto Simoes / J. Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
OpenSubtitles(开放字幕)语料库:P. Lison 和 J. Tiedemann,2016 年,《 OpenSubtitles2016:从影视字幕中提取大型平行语料库》(OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles),第十届国际语言资源与评价会议论文集(LREC '2016)。
DGT(欧盟委员会)语料库:JRC / J. Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
MultiUN 语料库:《 MultiUN:联合国文献多语种语料库》(MultiUN: A Multilingual corpus from United Nation Documents),Andreas Eisele 和 Yu Chen,LREC '2010 / J. Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
无版权图书语料库: http://farkastranslations.com/bilingual_books.php J. Tiedemann, 2012,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
TED2013 语料库: CASMACAT / J. Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
Wikipedia 平行语料库:《主语对齐可比语料库的构建及真实平行句子对的挖掘》(Building Subject-aligned Comparable Corpora and Mining it for Truly Parallel Sentence Pairs.),Procedia Technology,18,Elsevier,第 126~132 页,2014 年 / J. Tiedemann,2012 年,《 OPUS 中的并行数据、工具和接口》(Parallel Data, Tools and Interfaces in OPUS),第八届国际语言资源与评价会议论文集(LREC '2012)。
作者介绍:
Adam Geitgey,对计算机和机器学习感兴趣,喜欢撰写有关这些方面的文章。
原文链接:

