本文介绍的仓库包含用Python实现的流行的机器学习算法的示例,后面将解释它们的数学原理。每个算法都有交互式Jupyter笔记本演示,允许你使用训练数据、算法配置和立即查看浏览器中的图表并预测结果。

▲图片来源:https://vas3k.ru/blog/machine_learning/
这个项目的目的不是让大家通过使用第三方库一行代码实现机器学习算法,而是从零开始动手实现这些算法,从而更好地理解每种算法背后的数学机制。这就是为什么所有的算法实现在这里都被称为“homemade”,而不是单纯为了跑通算法。
https://github.com/trekhleb/homemade-machine-learning#homemade-machine-learning
01 监督学习
在监督学习中,我们有一组训练数据作为输入,每组训练集都有一组标签或“正确答案”作为输出。然后我们训练我们的模型(机器学习算法参数),以便正确地将输入映射到输出(进行正确的预测)。最终目的是找到这样的模型参数,即使对于新的输入示例,也可以成功地继续正确的输入→输出映射(预测)。
1. 回归
在回归问题中,我们做了真正的价值预测。我们试图沿着训练示例绘制线/平面/n维平面。
使用例子:股票价格预测,销售分析,数字依赖等。
Linear Regression 线性回归
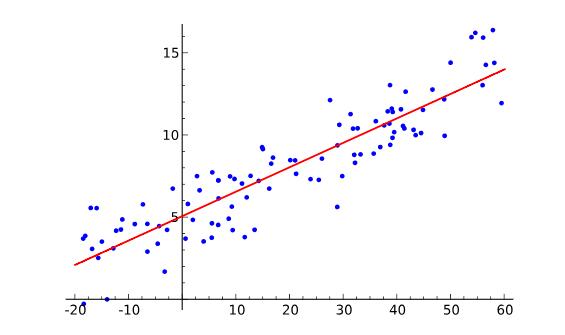
数学 | 理论、链接及更多的阅读资料
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/linear_regression
代码 | 实现示例
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/linear_regression/linear_regression.py
Demo | 单变量线性回归:用GDP预测城市幸福指数

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/linear_regression/univariate_linear_regression_demo.ipynb
Demo | 多元线性回归:用GDP和freedom index预测城市幸福指数

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/linear_regression/multivariate_linear_regression_demo.ipynb
Demo | 非线性回归:用多项式和正弦特征的线性回归预测非线性依赖关系

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/linear_regression/non_linear_regression_demo.ipynb
2. 分类
在分类问题中,我们将输入的例子按一定的特征进行分割。
使用示例:垃圾邮件过滤、语言检测、查找类似文档、手写字母识别等。
Logistic Regression 逻辑回归

数学 | 理论、链接及更多的阅读资料
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/logistic_regression
代码 | 实现示例
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/logistic_regression/logistic_regression.py
Demo | 逻辑回归-线性边界:基于花瓣长度和花瓣宽度的鸢尾花类预测

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/logistic_regression/logistic_regression_with_linear_boundary_demo.ipynb
Demo | 逻辑回归-非线性边界:基于Param_1和Param_2的微芯片有效性预测

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/logistic_regression/logistic_regression_with_non_linear_boundary_demo.ipynb
Demo | 多元逻辑回归-MNIST:从28x28像素图像中识别手写数字

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/logistic_regression/multivariate_logistic_regression_demo.ipynb
Demo | 多元逻辑回归-Fashion MNIST:从28x28像素图像中识别服装类型

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/logistic_regression/multivariate_logistic_regression_fashion_demo.ipynb
02 无监督学习
无监督学习是机器学习中的一个分支,它从未被标记、分类的数据中学习。无监督学习不是对反馈做出响应,而是根据每一新数据中是否存在此类共性来识别数据中的共性并作出反应。
1. 聚类
在聚类问题中,我们用未知特征分割训练实例。算法本身决定了用于分割的特征。
使用示例:市场分割、社交网络分析、组织计算集群、天文数据分析、图像压缩等。
K-means Algorithm
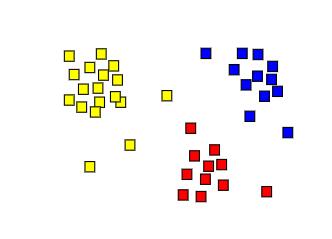
数学 | 理论、链接及更多的阅读资料
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/k_means
代码 | 实现示例
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/k_means/k_means.py
Demo | 基于花瓣长度和花瓣宽度将鸢尾花分割成簇clusters

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/k_means/k_means_demo.ipynb
2. 异常检测
异常检测是指通过与大多数数据显著不同而引起怀疑的稀有项目、事件或观测的识别。
使用示例:入侵检测、欺诈检测、系统运行状况监视、从数据集中删除异常数据等。
Anomaly Detection using Gaussian Distribution 基于高斯分布的异常检测
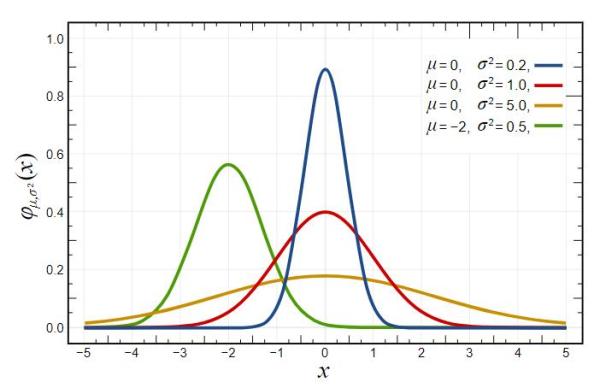
数学 | 理论、链接及更多的阅读资料
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/anomaly_detection
代码 | 实现示例
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/anomaly_detection/gaussian_anomaly_detection.py
Demo | 在服务器操作参数(如延迟和阈值)中查找异常

https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/anomaly_detection/anomaly_detection_gaussian_demo.ipynb
03 神经网络
神经网络本身不是一种算法,而是许多不同机器学习算法协同工作和处理复杂数据输入的框架。
使用示例:作为所有其他算法的替代,应用于图像识别、语音识别、图像处理(应用特定风格)、语言翻译等。
Multilayer Perceptron (MLP) 多层感知机
数学 | 理论、链接及更多的阅读资料
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/neural_network
代码 | 实现示例
https://github.com/trekhleb/homemade-machine-learning/blob/master/homemade/neural_network/multilayer_perceptron.py
Demo | 从28x28像素图像中识别手写数字
https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/neural_network/multilayer_perceptron_demo.ipynb
Demo | 从28x28像素图像中识别衣服类型
https://nbviewer.jupyter.org/github/trekhleb/homemade-machine-learning/blob/master/notebooks/neural_network/multilayer_perceptron_fashion_demo.ipynb
04 机器学习地图

1. Prerequisites
安装Python:
确保你的机器上安装了python。你可能希望使用venv标准python库来创建虚拟环境,并从本地项目目录安装python、pip和所有依赖的包,以避免干扰系统范围的包及其版本。
安装 dependencies:
pip install -r requirements.txt
2. Launching Jupyter Locally
项目中的所有演示都可以直接在浏览器中运行,而无需在本地安装jupyter。但是,如果你想在本地启动jupyter记事本,可以从项目的根文件夹运行以下命令:
jupyter notebook
在此之后,jupyter笔记本将可由http://localhost:8888.访问。
3. Launching Jupyter Remotely
每个算法部分都包含到Jupyter NBViewer的演示链接。这是Jupyter笔记本的快速在线预览器,你可以在浏览器中看到演示代码、图表和数据,而无需在本地安装任何内容。如果你想改变代码和实验演示笔记本,需要启动笔记本的活页夹,只需单击NBViewer右上角的“Execute on binder”链接即可完成此操作。

4. Datasets
可在数据文件夹中找到用于Jupyter笔记本演示的数据集列表:

