AI基础设施包括芯片和深度学习框架。芯片是算力平台,深度学习框架相当于编程生产力平台,堪称人工智能的大脑和灵魂,被视为人工智能领域的操作系统。
本节将介绍深度学习领域中常用的10种深度学习框架,包括MindSpore、PaddlePaddle、PyTorch及TensorFlow等。
1.MindSpore
2020年3月28日,华为在2020开发者大会上宣布全场景AI计算框架MindSpore在码云正式开源,企业级AI应用开发者套件ModelArts Pro也在华为云上线。该框架是一款支持端、边、云独立/协同的统一训练和推理框架。图3-23展示了MindSpore框架的结构。
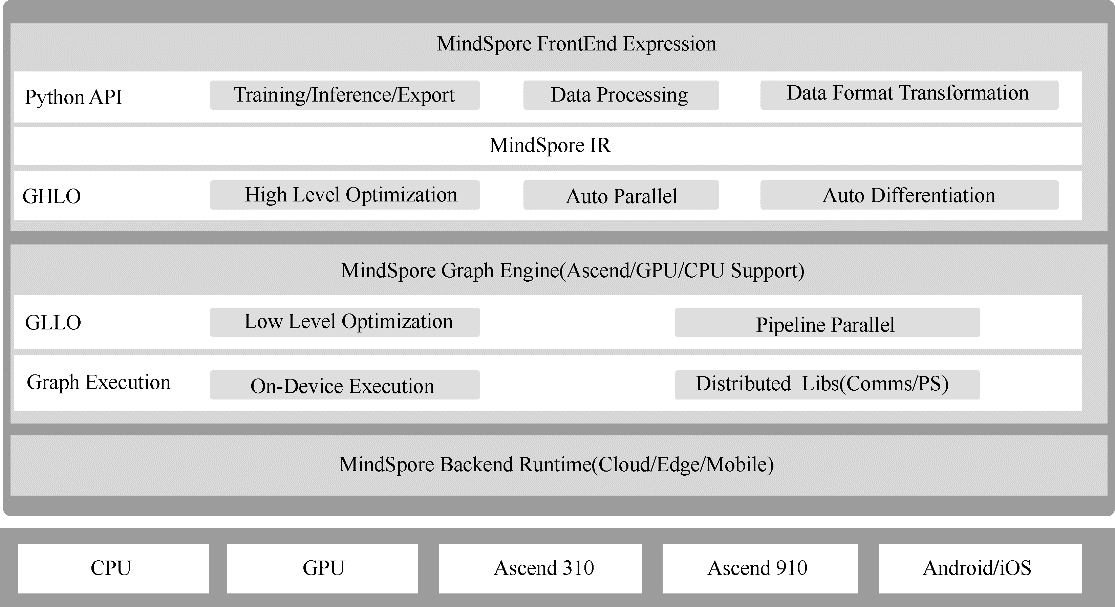
图3-23 MindSpore框架的结构
其API包括Python版本、C++版本及Java版本,MindSpore旨在提升数据科学家和算法工程师的开发体验,并为Ascend AI处理器提供原生支持及软硬件协同优化。图3-24所示即为MindSpore官网。
图3-24 MindSpore官网
2.MegEngine
2020年3月25日,北京旷视科技有限公司宣布开源其AI生产力平台Brain++的核心组件——MegEngine。图3-25展示了MegEngine的架构,它是一个快速、可扩展、易于使用且支持自动求导的深度学习框架,包括三个特性——动静结合的训练能力、训练推理一体化及全平台高效支持。
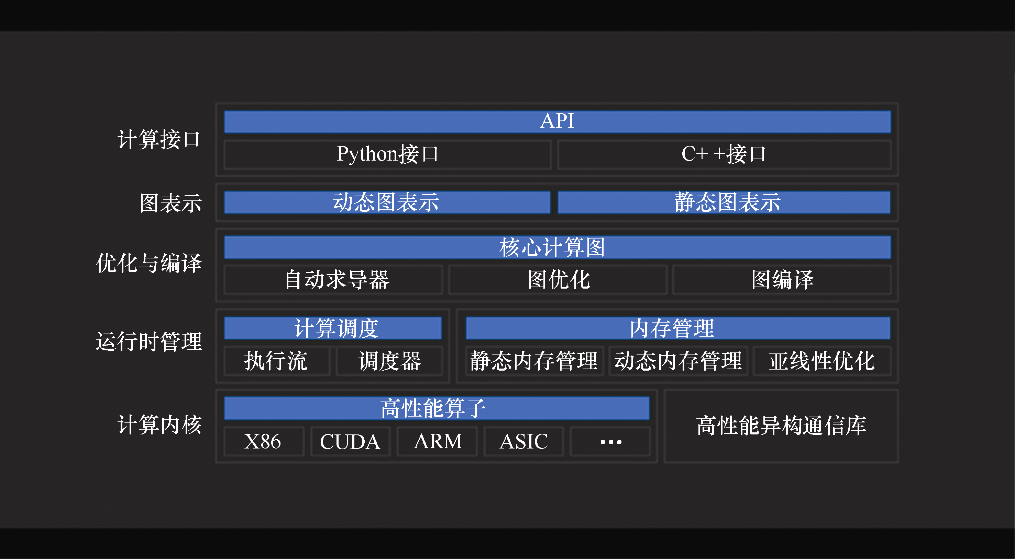
图3-25 MegEngine的架构
除此之外,为了方便开发者迁移并降低学习成本,旷视团队还对MegEngine框架做了全面升级,在整个框架的接口设计及接口命令等方面,尊重开发者在PyTorch机器学习和数学计算的使用习惯,让开发者可以在最短时间内快速上手。MegEngine官网如图3-26所示。
图3-26 MegEngine官网
值得一提的是,为了方便开发者学习,旷视团队还上线了MegStudio在线深度学习开发平台,提供数据、模型及免费的算力服务,帮助开发者快速、高效地进行深度学习开发。MegStudio官网如图3-27所示。
图3-27 MegStudio官网
3.Jittor
2020年3月20日,北京信息科学与技术国家研究中心可视媒体智能计算团队宣布开源其深度学习框架——Jittor(计图)。Jittor官网如图3-28所示。
图3-28 Jittor官网
该框架完全基于动态编译,内部使用创新的元算子和统一计算图。元算子和NumPy一样易于使用,并且超越NumPy,能够实现更复杂更高效的操作。而统一计算图则融合了静态计算图和动态计算图的优点,在易于使用的同时,提供了高性能的优化。图3-29展示了Jittor与TensorFlow和PyTorch的特性对比。
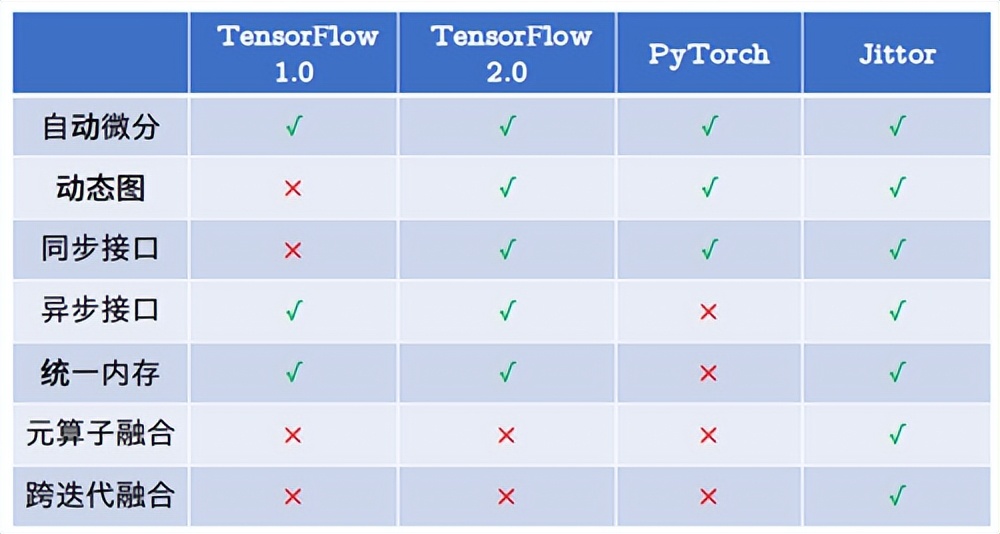
图3-29 框架比较(图片来源:清华大学官网)
4.PaddlePaddle
2018年7月,百度开源了其深度学习框架飞桨(PaddlePaddle v0.14),该版本包含CV、NLP、语音、强化学习等模型。经过大约3年的发展,2021年3月,飞桨2.0正式版发布,该框架以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台,集深度学习核心训练与推理框架、基础模型库、端到端开发套件和丰富的工具组建于一体,可帮助开发者快速实现AI想法,快速上线AI业务。值得一提的是,百度还为我们提供了在线深度学习平台AI Studio。图3-30所示即为飞桨官网。
图3-30 飞桨官网
5.NCNN
NCNN 是腾讯优图实验室的某个开源项目,是一个为手机端优化的高性能神经网络前向计算框架。该框架从设计之初就考虑手机端的部署和使用,无第三方依赖,跨平台,手机端CPU的速度快于目前所有已知的开源框架。基于NCNN,开发者能够将深度学习算法轻松移植到手机端并高效执行,开发出人工智能APP。NCNN目前已在腾讯多款应用(如QQ、Qzone、天天P图、微信等)中使用。图3-31所示即为腾讯优图官网。
图3-31 腾讯优图官网
6.Caffe
2013年9月,贾扬清在GitHub正式开源Caffe,该框架的英文全称为Convolutional Architecture For Fast Embedding,它是一个清晰、高效的深度学习框架,核心语言是C++,其代码和框架都比较简单,代码易于扩展,运行速度快,也适合深入分析,十分适合初学者学习。
2017年4月18日,Meta(原Facebook)开源了Caffe2,其开发重点是性能和跨平台的部署,而Meta旗下的PyTorch则专注于快速原型设计和研究的灵活性。图3-32所示即为Caffe2官网。
图3-32 Caffe2官网
7.MXNet
2016年11月,亚马逊正式开源MXNet。该框架是一个轻量级、可移植、灵活的分布式深度学习框架,支持CNN、RNN和LSTM模型,为图像、手写文字、语音识别和预测及自然语言处理提供了出色的工具,其优势在于对分布式的支持和对内存、显存的优化。同样的深度学习模型在MXNet中往往占用较少的内存和显存。MXNet官网如图3-33所示。
图3-33 MXNet官网
8.Keras
2015年3月,谷歌正式开源Keras,其最初版本同时支持CNN和RNN,该框架以TensorFlow、Theano、CNTK作为底层引擎,并将其函数统一封装。Keras官网如图3-34所示。

图3-34 Keras官网
2017年,Keras成为TensorFlow的默认API。至此,谷歌大力主推Keras+TensorFlow的深度学习框架,在TensorFlow 2.4.1版本中,Keras已经集成到TensorFlow中,并以tf.keras模块供开发者使用,如图3-35所示。
图3-35 tf.keras模块
9.PyTorch
2017年1月,Meta人工智能研究院在GitHub上开源了PyTorch深度学习框架,Meta用Python重写了基于Lua语言的深度学习库Torch,并继承了其灵活、动态的编程环境和友好的界面,支持以快速和灵活的方式构建动态神经网络,还允许在训练过程中快速更改代码而不妨碍其性能,还在此基础上新增了自动求导系统,使其成为流行的动态图框架。
PyTorch重构和统一了Caffe2和PyTorch 0.4框架的代码库,删除了重复的组件并共享上层抽象,支持高效的图模式执行、移动端部署和广泛的供应商集成等,同时具有PyTorch和Caffe2的优势。PyTorch官网如图3-36所示。
图3-36 PyTorch官网
10.TensorFlow
2015年11月,谷歌正式开源TensorFlow。该框架由谷歌大脑团队开发,是一款用于机器学习的端到端开源平台,它拥有一个全面而灵活的生态系统。其中包含各种工具、库和社区资源,可以帮助开发者轻松地构建和部署由机器学习提供支持的应用。该框架具有如下3个显著的特点。
轻松构建模型:在即时执行环境中使用Keras等直观的高阶API轻松地构建和训练机器学习模型,该环境使我们能够快速迭代模型并轻松地调试模型。
随时随地进行可靠的机器学习生产:无论使用哪种语言,开发人员都可以在云端、本地、浏览器或设备上轻松地训练和部署模型。
强大的研究试验:快速地将概念转换成代码,然后创建出先进的模型,并最终对外发布。
目前,TensorFlow是所有深度学习框架中生态最完整的框架之一,它由C++语言开发,支持Python、JavaScript、C++、Java、Swift、R等语言的调用。图3-37所示即为TensorFlow官网。
图3-37 TensorFlow官网

