机器学习方面没有免费的午餐。因此,确定使用哪种算法取决于许多因素:从手头的问题类型,到预期的输出类型。本文介绍了您在为数据集探究合适的机器学习方法时,须关注的几个考量因素。

作者丨Yogita Kinha
编译丨布加迪
策划丨孙淑娟
如何选择合适的机器学习算法?
这个问题没有直接而明确的答案。答案取决于许多因素,比如问题陈述和您想要的输出类型、数据的类型和大小、可用的计算时间、特征数量以及数据中的观测等。
以下是选择算法时要考虑的几个重要因素。
1.训练数据的大小
通常建议收集大量数据以获得可靠的预测。然而,数据的可用性往往是制约因素。因此,如果训练数据较小,或者数据集的观测数量较少,特征数量较多(比如遗传或文本数据),应选择高偏差 / 低方差的算法,比如线性回归、朴素贝叶斯或线性 SVM。
如果训练数据足够大,观测数量与特征数量相比较多,可以选择低偏差 / 高方差算法,比如 KNN、决策树或内核 SVM。
2.输出的准确性及 / 或可解释性
模型的准确性意味着函数预测给定观测的响应值,这个响应值接近该观测的实际响应值。高度可解释的算法(线性回归等限制性模型)意味着,人们可以轻松理解任何单个预测变量如何与响应相关联,而灵活的模型提供了更高的准确性,但是以低可解释性为代价。

图 1. 使用不同的统计学习方法,表示了准确性和可解释性之间的取舍
一些算法称为限制性算法,因为它们生成映射函数的一小批形状。比如说,线性回归是一种限制性方法,因为它只能生成直线等线性函数。
一些算法称为灵活性算法,因为它们生成映射函数的一大批形状。比如说,k=1 的 KNN 非常灵活,因为它会考虑每个输入数据点以生成映射输出函数。下图显示了灵活性算法和限制性算法之间的取舍。
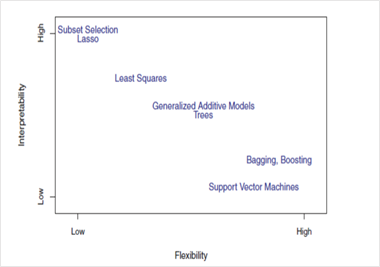
图 2. 使用不同的统计学习方法,表示了灵活性和可解释性之间的取舍
现在,使用哪种算法取决于业务问题的目标。如果目标是推理,限制性模型更好,因为它们极易于解释。如果目标是更高的准确性,灵活性模型更好。随着某种方法的灵活性提高,其可解释性一般会降低。
3.速度或训练时间
更高的准确性通常意味着更长的训练时间。此外,算法需要更多时间来训练庞大的训练数据。在实际应用中,算法的选择主要取决于这两个因素。
朴素贝叶斯、线性和逻辑回归等算法易于实现,且运行迅速。像需要调整参数的 SVM、高收敛时间的神经网络和随机森林等算法需要大量的时间来训练数据。
4.线性
许多算法的运作基于这个假设:类可以被一条直线(或更高维度的模拟)来分隔。示例包括逻辑回归和支持向量机。线性回归算法假设数据趋势遵循一条直线。如果数据是线性的,这些算法的性能就相当不错。
然而,数据并不总是线性的,因此我们需要可以处理高维和复杂数据结构的其他算法。例子包括内核 SVM、随机森林和神经网络。
找出线性的最佳方法是拟合线性线,或者运行逻辑回归或 SVM,以检查剩余错误。较多的错误意味着数据不是线性的,需要复杂的算法来拟合。
5.特征数量
数据集可能有大量特征,这些特征可能并非全部相关、重要。针对某种类型的数据,比如遗传数据或文本数据,与数据点的数量相比,特征的数量可能非常大。
大量特征会阻碍一些学习算法,从而使训练时间过长。SVM 更适合具有大片特征空间和较少观测的数据。应该使用 PCA 和特征选择技术,以降低维度,并选择重要的特征。
这是一份方便的速查表,详细表明了可用于不同类型的机器学习问题的算法。
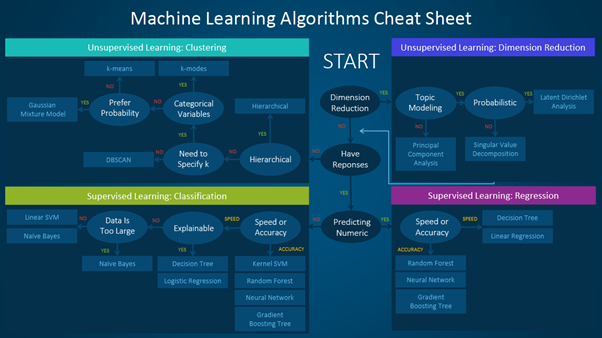
机器学习算法可以分为监督学习、无监督学习和强化学习,我在之前的博客中讨论过(https://www.edvancer.in/understanding-artificial-intelligence-machine-learning-and-data-science/)。这篇文章逐步介绍了如何使用速查表的过程速查表主要分为两种学习类型:
在训练数据具有对应于输入变量的输出变量这种情况下,采用监督学习算法。该算法分析输入数据,并学习函数,以映射输入变量和输出变量之间的关系。
监督学习可以进一步分为回归、分类、预测和异常检测。
当训练数据没有响应变量时,使用无监督学习算法。这类算法试图找到数据中的内在模式和隐藏结构。聚类算法和降维算法是两类典型的无监督学习算法。
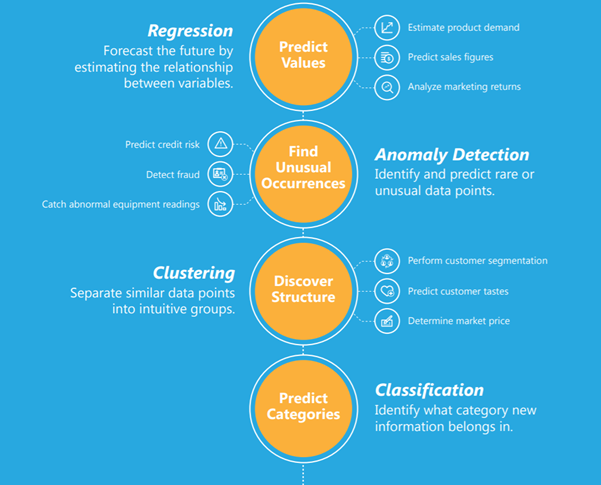
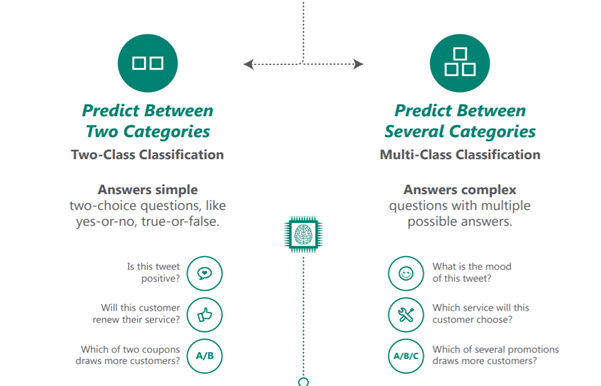
下面的信息图简单地解释了回归、分类、异常检测和聚类以及可以运用这每一种算法的示例。
尝试解决新问题时须考虑的要点如下:
定义问题。问题的目标是什么?
探索数据,并熟悉数据。
从基本模型开始,构建基准模型,然后尝试较复杂的方法。
话虽如此,始终记得“更好的数据常常胜过更好的算法”。设计好的特征同等重要。尝试一堆算法,并比较各自的性能,为您的具体任务选择最佳算法。此外,尝试集成学习(ensemble)方法,因为这种方法提供的准确性通常好得多。

