线上一个系统,在某次高峰期间MQ中间件故障的情况下,触发了降级机制,结果降级机制触发之后运行了一小会儿,突然系统就完全卡死,无法响应任何请求。
这篇文章,我们继续给大家聊聊另外一个线上系统在生产环境遇到的问题。
一、背景介绍
背景情况是这样:线上一个系统,在某次高峰期间MQ中间件故障的情况下,触发了降级机制,结果降级机制触发之后运行了一小会儿,突然系统就完全卡死,无法响应任何请求。
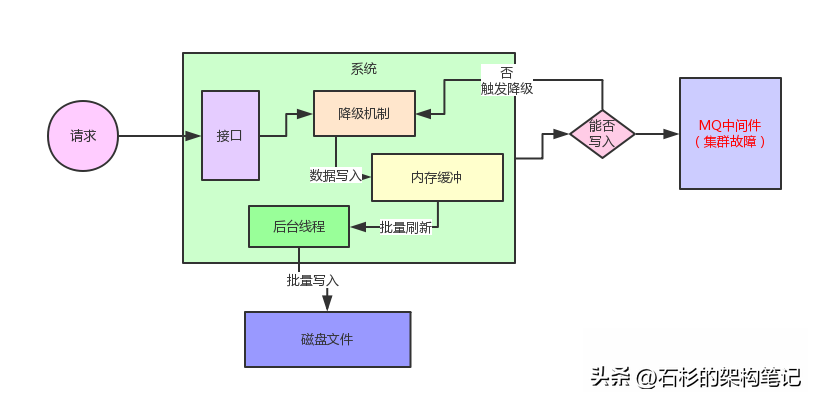
给大家简单介绍一下这个系统的整体架构,这个系统简单来说就是有一个非常核心的行为,就是往MQ里写入数据,但是这个往MQ里写入的数据是非常核心及关键的,绝对不容许有丢失。
所以最初就设计了一个降级机制,如果一旦MQ中间件故障,那么这个系统立马就会把核心数据写入本地磁盘文件。
但是如果说在高峰期并发量比较高的情况下,接收到一条数据立马同步写本地磁盘文件,这个性能绝对是极其差的,会导致系统自身的吞吐量瞬间大幅度下降,这个降级机制是绝对无法在生产环境运行的,因为自己就会被高并发请求压垮。
因此当时设计的时候,对降级机制进行了一番精心的设计。
我们的核心思路是一旦MQ中间件故障,触发降级机制之后,系统接收到一条请求不是立马写本地磁盘,而是采用内存双缓冲 + 批量刷磁盘的机制。
简单来说,系统接收到一条消息就会立马写内存缓冲,然后开启一个后台线程把内存缓冲的数据刷新到磁盘上去。
整个过程,大家看看下面的图,就知道了。
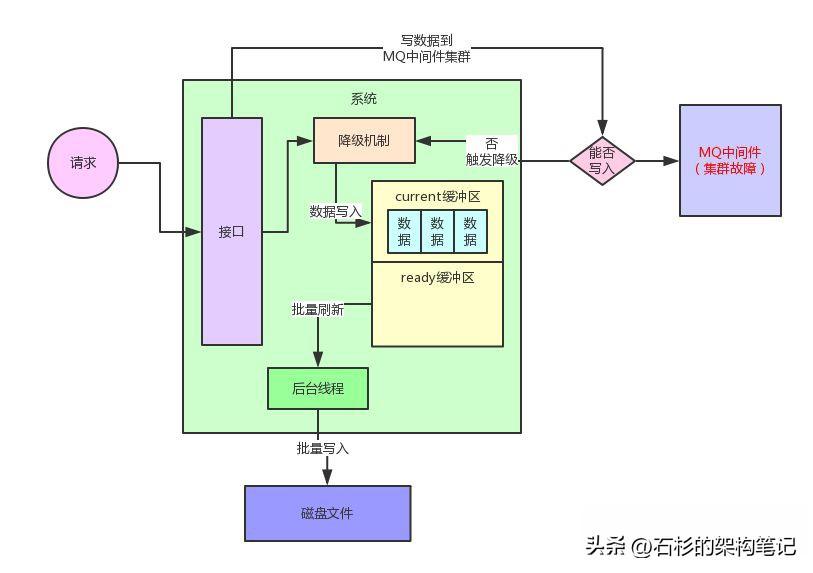
这个内存缓冲实际在设计的时候,分为了两个区域。
一个是current区域,用来供系统写入数据,另外一个是ready区域,用来供后台线程刷新数据到磁盘里去。
每一块内存区域设置的缓冲大小是512kb,系统接收到请求就写current缓冲区,但是current缓冲区总共就512kb的内存空间,因此一定会写满。
同样,大家结合下面的图,一起来看看。
current缓冲区写满之后,就会交换current缓冲区和ready缓冲区。交换过后,ready缓冲区承载了之前写满的512kb的数据。
然后current缓冲区此时是空的,可以继续接着系统继续将新来的数据写入交换后的新的current缓冲区。
整个过程如下图所示:
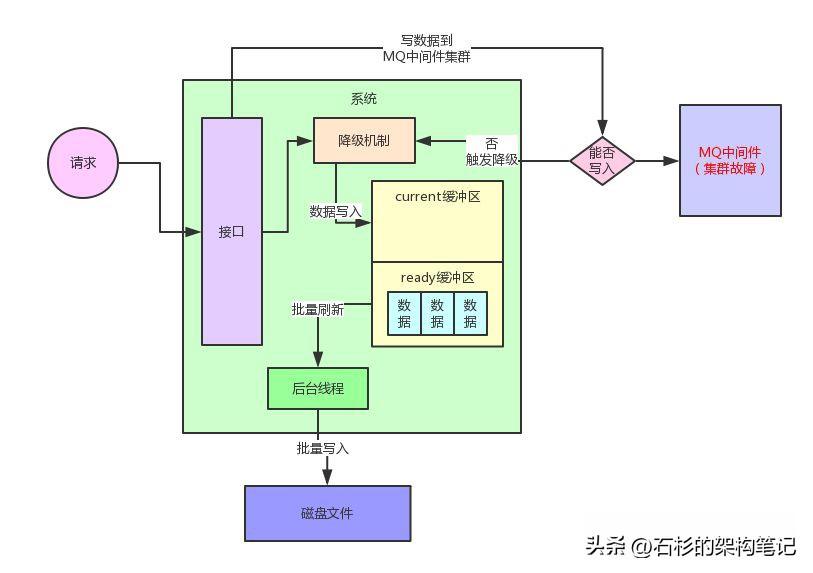
此时,后台线程就可以将ready缓冲区中的数据通过Java NIO的API,直接高性能append方式的写入到本地磁盘文件里。
当然,这里后台线程会有一整套完善的机制,比如说一个磁盘文件有固定大小,如果达到了一定大小,自动开启一个新的磁盘文件来写入数据。
二、埋下隐患
好!通过上面一套机制,即使是高峰期,也能顺利的抗住高并发的请求,一切看起来都很美好!
但是,当时这个降级机制在开发时,我们采取的思路,为后面埋下了隐患!
当时采取的思路是:如果current缓冲区写满了之后,所有的线程全部陷入一个while循环无限等待。
等到什么时候呢?一直需要等到ready缓冲区的数据被刷到磁盘文件之后,清空掉ready缓冲区,然后跟current缓冲区进行交换。
这样current缓冲区要再次变为空的缓冲区,才可以让工作线程继续写入数据。
但是大家有没有考虑过一个异常的情况有可能会发生?
就是后台线程刷新ready缓冲区的数据到磁盘文件,实际上也是需要一点时间的。
万一在他刷新数据到磁盘文件的过程中,current缓冲区突然也被写满了呢?
此时就会导致系统的所有工作线程无法写入current缓冲区,线程全部卡死。
给大家上一张图,看看这个问题!
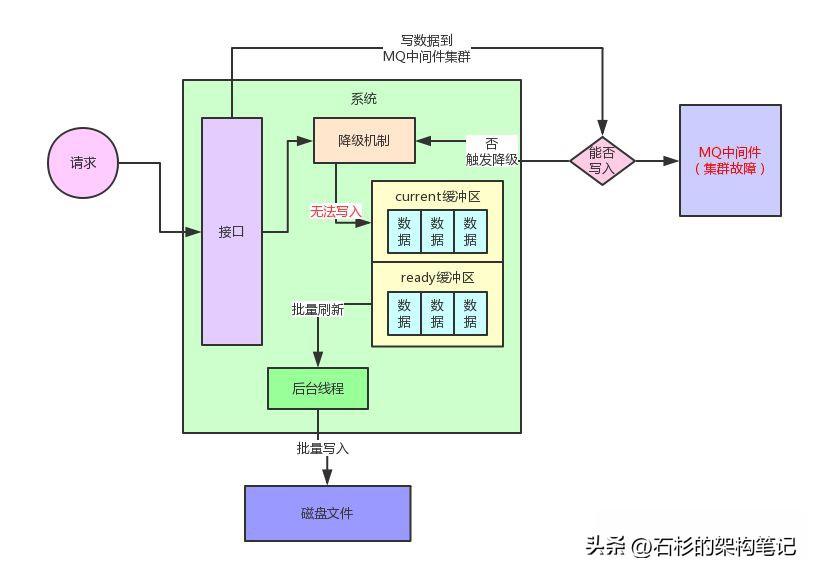
这个就是系统的降级机制的双缓冲机制最根本的问题了,在开发好这套降级机制之后,采用正常的请求压力测试过,发现两块缓冲区在设置为512kb的情况下,运作良好,没有什么问题。
三、高峰请求,问题爆发
但是问题就出在高峰期上了。某一次高峰期,系统请求压力达到了平时的10倍以上。
当然正常流程下,高峰期的时候,写请求其实也是直接全部写到MQ中间件集群去的,所以哪怕你高峰期流量增加10倍也无所谓,MQ集群是可以天然抗高并发的。
但是当时不幸的是,在高峰期的时候,MQ中间件集群突然临时故障,这也是一年遇不到几次的。
这就导致这个系统突然触发了降级机制,然后就开始写入数据到内存双缓冲里面去。
要知道,此时是高峰期啊,请求量是平时正常的10倍!因此10倍的请求压力瞬间导致了一个问题的发生。
这个问题就是瞬时涌入的高并发请求一下将current缓冲区写满,然后两个缓冲区交换,后台线程开始刷新ready缓冲区的数据到磁盘文件里去。
结果因为高峰期请求涌入过快,导致ready缓冲区的数据还没来得及刷新到磁盘文件,此时current缓冲区又突然写满了。。。
这就尴尬了,线上系统瞬间开始出现异常。。。
典型的表现就是,所有机器上部署的实例全部线程都卡死,处于wait的状态。
四、定位问题,对症下药
于是,这套系统开始在高峰期无法响应任何请求。后来经过线上故障紧急排查、定位和抢修,才解决了这个问题。
其实说来解决方法也很简单,我们通过jvm dump出来快照进行分析,查看系统的线程具体是卡在哪个环节,然后发现大量线程卡死在等待current缓冲区的地方。
这就很明显知道原因了,解决方法就是对线上系统扩容双段缓冲的大小,从512kb扩容到一个缓冲区10mb。
这样在线上高峰期的情况下,也可以稳稳的让降级机制的双缓冲机制流畅的运行,不会说瞬间高峰涌入的请求打满两块缓冲区。
因为缓冲区越大,就可以让ready缓冲区被flush到磁盘文件的过程中,current缓冲区没那么快被打满。
但是这个线上故障反馈出来的一个教训,就是对系统设计和开发的任何较为复杂的机制,都必须要参照线上高峰期的最大流量来压力测试。只有这样,才能确保任何在系统上线的复杂机制可以经得起线上高峰期的流量的考验。
责任编辑:武晓燕来源: 今日头条

