大家好!我是"无敌码农"。今天的文章将给大家分享Java并发编程相关的知识点,虽然类似的文章已有很多,但本文将以更贴近实际使用场景的方式进行阐述。具体将对Java常见的并发编程方式和手段进行总结,以便可以从使用角度更好地感知Java并发编程带来的效果,从而为后续更深入的理解Java并发机制进行铺垫。
Java多线程概述
在Java中使用多线程是提高程序并发响应能力的重要手段,但同时它也是一把双刃剑;如果使用不当也很容易导致程序出错,并且还很难直观地找到问题。这是因为:1)、线程运行本身是由操作系统调度,具有一定的随机性;2)、Java共享内存模型在多线程环境下很容易产生线程安全问题;3)、不合理的封装依赖,极容易导致发布对象的不经意逸出。
所以,要用好多线程这把剑,就需要对Java内存模型、线程安全问题有较深的认识。但由于Java丰富的生态,在实际研发工作中,需要我们自己进行并发处理的场景大都被各类框架或组件给屏蔽了。这也是造成很多Java开发人员对并发编程意识淡薄的主要原因。
首先从Java内存模型的角度理解下使用多线程编程最核心的问题,具体如下图所示:

如上图所示,在Java内存模型中,对于用户程序来说用得最频繁的就是堆内存和栈内存,其中堆内存主要存放对象及数组,例如由new()产生的实例。而栈内存则主要是存储运行方法时所需的局部变量、操作数及方法出口等信息。
其中堆内存是线程共享的,一个类被实例化后生成的对象、及对象中定义的成员变量可以被多个线程共享访问,这种共享主要体现在多个线程同时执行、同一个对象实例的某个方法时,会将该方法中操作的对象成员变量分别以多个副本的方式拷贝到方法栈中进行操作,而不是直接修改堆内存中对象的成员变量值;线程操作完成后,会再次将修改后的变量值同步至堆内存中的主内存地址,并实现对其他线程的可见。
这个过程虽然看似行云流水,但在JVM中却至少需要6个原子步骤才能完成,具体如下图所示:
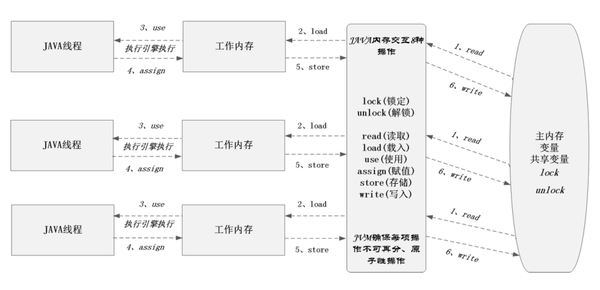
如上图所示,在不考虑对共享变量进行加锁的情况下,堆内存中一个对象的成员变量被线程修改大概需要以下6个步骤:
1、read(读取):从堆内存中的读取要操作的变量;
2、load(载入):将读取的变量拷贝到线程栈内存;
3、use(使用):将栈内存中的变量值传递给执行引擎;
4、assign(赋值):将从执行引擎得到的结果赋值给栈内存中变量;
5、store(存储):将变更后的栈内存中的变量值传递到主内存;
6、write(写入):变更主内存中的变量值,此时新值对所有线程可见;
由此可见,每个线程都可以按这几个步骤并行操作同一个共享变量。可想而知,如果没有任何同步措施,那么在多线程环境下,该共享变量的值将变得飘忽不定,很难得到最终正确的结果。而这就是所谓的线程安全问题,也是我们在使用多线程编程时,最需要关注的问题!
线程池的使用
在实际场景中,多线程的使用并不是单打独斗,线程作为宝贵的系统资源,其创建和销毁都需要耗费一定的系统资源;而无限制的创建线程资源,也会导致系统资源的耗尽。所以,为了重复使用线程资源、限制线程的创建行为,一般都会通过线程池来实现。以Java Web服务中使用最广的Tomcat服务器举例,为了并行处理网络请求就使用了线程池,源码示例如下:
public boolean processSocket(SocketWrapperBase<S> socketWrapper, SocketEvent event, boolean dispatch) { try { if (socketWrapper == null) { return false; } SocketProcessorBase<S> sc = null; if (processorCache != null) { sc = processorCache.pop(); } if (sc == null) { sc = createSocketProcessor(socketWrapper, event); } else { sc.reset(socketWrapper, event); } //这里通过线程池对线程执行进行管理 Executor executor = getExecutor(); if (dispatch && executor != null) { executor.execute(sc); } else { sc.run(); } } catch (RejectedExecutionException ree) { getLog().warn(sm.getString("endpoint.executor.fail", socketWrapper) , ree); return false; } catch (Throwable t) { ExceptionUtils.handleThrowable(t); // This means we got an OOM or similar creating a thread, or that // the pool and its queue are full getLog().error(sm.getString("endpoint.process.fail"), t); return false; } return true; }上述代码为Tomcat源码使用线程池并发处理网络请求的示例,这里以Tomcat为例,主要是因为基于Spring Boot、Spring MVC开发的Web服务大都运行在Tomcat容器,而对于线程、线程池使用的复杂度都被屏蔽在中间件和框架中了,所以很多同学虽然写了不少Java代码,但在业务研发中额外使用线程的场景可能并不多,举这个例子的目的就是为了提升下并发编程的意识!
在Java中使用线程池的主要方式是Executor框架,该框架作为JUC并发包的一部分,为Java程序提供了一个灵活的线程池实现。其逻辑层次如下图所示:

如图所示,使用Executor框架,既可以通过直接自定义配置、扩展ThreadPoolExecutor来创建一个线程池,也可以通过Executors类直接调用“newSingleThreadExecutor()、newFixedThreadPool()、newCachedThreadPool()”这三个方法来创建具有一定功能特征的线程池。
除此之外,也可以通过自定义配置、扩展ScheduledThreadPoolExecutor来创建一个具有周期性、定时功能的线程池,例如线程10s后运行、线程每分钟运行一次等。同样,与ThreadPoolExecutor一样,如果不想自定义配置,也可以通过Executors类直接调用“newScheduledThreadPool()、newSingleThreadScheduledExecutor()”这两个方法来分别创建具备自动线程规模扩展能力和线程池中只允许有单个线程的特定线程池。
而ForkJoinPool是jdk1.8以后新增的一种线程池实现类型,类似于Fork-Join框架所支持的功能。这是一种可以将一个大任务拆分成多个任务队列,并具体分配给不同线程处理的机制,而关键的特性在于,通过窃取算法,某个线程在执行完本队列任务后,可以窃取其他队列的任务进行执行,从而最大限度提高线程的利用效率。
在实际应用中,虽然可以通过Executors方便的创建单个线程、固定线程或具备自动收缩能力的线程池,但一般还是建议直接通过ThreadPoolExecutor或ScheduledThreadPoolExecutor自定义配置,这主要是因为Executors默认创建的线程池,很多采用的是无界队列,例如LinkedBlockingQueue,这样线程就可以被无限制的添加都线程池的任务执行队列,如果请求量过大容易造成OOM。
接下来以一个实际的例子来演示通过ThreadPoolExecutor如何自定义配置一个业务线程池,具体如下:
1)、配置一个线程池类
public final class SingleBlockPoolExecutor { /** * 自定义配置线程池(线程池核心线程数、最大线程数、存活时间设置、采用的队列类型、线程工厂类、线程池拒绝处理类) */ private final ThreadPoolExecutor pool = new ThreadPoolExecutor(30, 100, 5, TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(100), new BlockThreadFactory(), new BlockRejectedExecutionHandler()); public ThreadPoolExecutor getPool() { return pool; } private SingleBlockPoolExecutor() { } /** * 定义线程工厂 */ public static class BlockThreadFactory implements ThreadFactory { private AtomicInteger count = new AtomicInteger(0); @Override public Thread newThread(Runnable r) { Thread t = new Thread(r); String threadName = SingleBlockPoolExecutor.class.getSimpleName() + "-" + count.addAndGet(1); t.setName(threadName); return t; } } /** * 定义线程池拒绝机制处理类 */ public static class BlockRejectedExecutionHandler implements RejectedExecutionHandler { @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { try { //被拒线程再次返回阻塞队列进行等待处理 executor.getQueue().put(r); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } } /** * 在静态内部类中持有单例类的实例,并且可直接被初始化 */ private static class Holder { private static SingleBlockPoolExecutor instance = new SingleBlockPoolExecutor(); } /** * 调用getInstance方法,事实上是获得Holder的instance静态属性 * * @return */ public static SingleBlockPoolExecutor getInstance() { return Holder.instance; } /** * 线程池销毁方法 */ public void destroy() { if (pool != null) { //线程池销毁 pool.shutdownNow(); } } }如上述代码所示,通过单例模式配置了一个线程池。在对ThreadPoolExecutor的配置中,需要设置“核心线程数、最大线程数、存活时间设置、采用的队列类型、线程工厂类、线程池拒绝处理类”,这几个核心参数。
2)、定义系统全局线程池管理类
public class AsyncManager { /** * 任务处理公共线程池 */ public static final ExecutorService service = SingleBlockPoolExecutor.getInstance().getPool(); }在应用中,除了框架定义的线程池外,如果自定义线程池,为了方便统一管理和使用,可以建立一个全局管理类,如上所示,该类通过静态变量的方式初始化了前面我们所定义的线程池。
3)、业务中使用
@Service @Slf4j public class OrderServiceImpl implements OrderService { @Override public CreateOrderBO createOrder(CreateOrderDTO createOrderDTO) { //1、同步处理核心业务逻辑 log.info("同步处理业务逻辑"); //2、通过线程池提交,异步处理非核心逻辑,例如日志埋点 AsyncManager.service.execute(() -> { System.out.println("线程->" + Thread.currentThread().getName() + ",正在执行异步日志处理任务"); }); return CreateOrderBO.builder().result(true).build(); } }如上代码所示,业务中需要通过线程池异步处理时,可以通过线程池管理类获取对应的线程池,并向其提交执行线程任务。
FutureTask实现异步结果返回
在使用Thread或Runnable实现的线程处理中,一般是不能返回线程处理结果的。但如果希望在调用线程异步处理完成后,能够获得线程异步处理的结果,那么就可以通过FutureTask框架实现。示例代码如下:
@Service @Slf4j public class OrderServiceImpl implements OrderService { @Override public CreateOrderBO createOrder(CreateOrderDTO createOrderDTO) { //Future异步处理返回执行结果 //定义接收线程执行结果的FutureTask对象 List<Future<Integer>> results = Collections.synchronizedList(new ArrayList<>()); //实现Callable接口定义线程执行逻辑 results.add(AsyncManager.service.submit(new Callable<Integer>() { @Override public Integer call() throws Exception { int a = 1, b = 2; System.out.println("Callable接口执行中"); return a + b; } })); //输出线程返回结果 for (Future<Integer> future : results) { try { //这里获取结果,等待时间设置200毫秒 System.out.println("a+b=" + future.get(200, TimeUnit.MILLISECONDS)); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } } //判断线程是否执行完毕,完毕则获取执行结果 return CreateOrderBO.builder().result(true).build(); } }如上述代码,如果希望线程返回执行结果,那么可以通过实现Callable接口定义线程类,并通过FutureTask接收线程处理结果。不过在实际使用时,需要注意线程暂时未执行完成情况下的业务处理逻辑。
CountDownLatch实现线程并行同步
在并发编程中,一个复杂的业务逻辑可以通过多个线程并发执行来提高速度;但如果需要同步等待这些线程执行完后才能进行后续的逻辑,那么就可以通过CountDownLatch来实现对多个线程执行的同步汇聚。其逻辑示意图如下:

从原理上看CountDownLatch实际上是在其内部创建并维护了一个volatile类型的整数计数器,当调用countDown()方法时,会尝试将整数计数器-1,当调用wait()方法时,当前线程就会判断整数计数器是否为0,如果为0,则继续往下执行,如果不为0,则使当前线程进入阻塞状态,直到某个线程将计数器设置为0,才会唤醒在await()方法中等待的线程继续执行。
常见的代码使用示例如下:
1)、创建执行具体业务逻辑的线程处理类
public class DataDealTask implements Runnable { private List<Integer> list; private CountDownLatch latch; public DataDealTask(List<Integer> list, CountDownLatch latch) { this.list = list; this.latch = latch; } @Override public void run() { try { System.out.println("线程->" + Thread.currentThread().getName() + ",处理" + list.size()); } finally { //处理完计数器递减 latch.countDown(); } } }该线程处理类,在实例化时接收除了待处理数据参数外,还会接收CountDownLatch对象,在执行完线程逻辑,注意,无论成功或失败,都需要调用countDown()方法。
2)、具体的使用方法
@Service @Slf4j public class OrderServiceImpl implements OrderService { @Override public CreateOrderBO createOrder(CreateOrderDTO createOrderDTO) { //CountDownLatch的使用示例 //模拟待处理数据生成 Integer[] array = {10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 101, 102}; List<Integer> list = new ArrayList<>(); Arrays.asList(array).stream().map(o -> list.add(o)).collect(Collectors.toList()); //对数据进行分组处理(5条记录为1组) Map<String, List<?>> entityMap = this.groupListByAvg(list, 6); //根据数据分组数量,确定同步计数器的值 CountDownLatch latch = new CountDownLatch(entityMap.size()); Iterator<Entry<String, List<?>>> it = entityMap.entrySet().iterator(); try { //将分组数据分批提交给不同线程处理 while (it.hasNext()) { DataDealTask dataDealTask = new DataDealTask((List<Integer>) it.next().getValue(), latch); AsyncManager.service.submit(dataDealTask); } //等待分批处理线程处理完成 latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } return CreateOrderBO.builder().result(true).build(); } }如上所示代码,在业务逻辑中如果处理数据量多,则可以通过分组的方式并行处理,而等待所有线程处理完成后,再同步返回调用方。这种场景就可以通过CountDownLatch来实现同步!
CycliBarrier栅栏实现线程阶段性同步
CountDownLatch的功能主要是实现线程的一次性同步。而在实际的业务场景中也可能存在这样的情况,执行一个阶段性的任务,例如”阶段1->阶段2->阶段3->阶段4->阶段5"。那么在并发处理这个阶段性任务时,就要在每个阶段设置栅栏,只有当所有线程执行到某个阶段点之后,才能继续推进下一个阶段任务的执行,其逻辑如图所示:
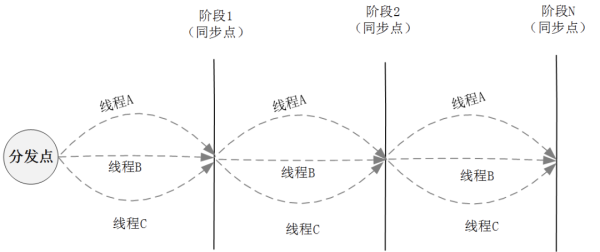
针对上述场景,就可以通过CycliBarrier来实现。而从实现上看,CyclicBarrier使用了基于ReentrantLock的互斥锁实现;在CyclicBarrier的内部有一个计数器 count,当count不为0时,每个线程在到达同步点会先调用await方法将自己阻塞,并将计数器会减1,直到计数器减为0的时候,所有因调用await方法而被阻塞的线程就会被唤醒继续执行。并进入下一轮阻塞,此时在new CyclicBarrier(parties) 时设置的parties值,会被赋值给 count 从而实现复用。
例如,计算某个部门的员工工资,要求在所有员工工资都计算完之后才能进行下一步整合操作。其代码示例如下:
@Slf4j @Service public class SalaryStatisticServiceImpl implements SalaryStatisticService { /** * 模拟部门员工存储数据 */ public static Map<String, List<EmployeeSalaryInfo>> employeeMap = Collections.synchronizedMap(new HashMap<>()); static { EmployeeSalaryInfo employeeA = new EmployeeSalaryInfo(); employeeA.setEmployeeNo("100"); employeeA.setBaseSalaryAmount(10000); employeeA.setSubsidyAmount(3000); EmployeeSalaryInfo employeeB = new EmployeeSalaryInfo(); employeeB.setEmployeeNo("101"); employeeB.setBaseSalaryAmount(30000); employeeB.setSubsidyAmount(3000); List<EmployeeSalaryInfo> list = new ArrayList<>(); list.add(employeeA); list.add(employeeB); employeeMap.put("10", list); } @Override public StatisticReportBO statisticReport(StatisticReportDTO statisticReportDTO) { //查询部门下所有员工信息(模拟) List<EmployeeSalaryInfo> employeeSalaryInfos = employeeMap.get(statisticReportDTO.getDepartmentNo()); if (employeeSalaryInfos == null) { log.info("部门员工信息不存在"); return StatisticReportBO.builder().build(); } //定义统计总工资的安全变量 AtomicInteger totalSalary = new AtomicInteger(); //开启栅栏(在各线程触发之后触发) CyclicBarrier cyclicBarrier = new CyclicBarrier(employeeSalaryInfos.size(), new Runnable() { //执行顺序-B1(随机) //该线程不会阻塞主线程 @Override public void run() { log.info("汇总已分别计算出的两个员工的工资->" + totalSalary.get() + ",执行顺序->B"); } }); //执行顺序-A for (EmployeeSalaryInfo e : employeeSalaryInfos) { AsyncManager.service.submit(new Callable<Integer>() { @Override public Integer call() { int totalAmount = e.getSubsidyAmount() + e.getBaseSalaryAmount(); log.info("计算出员工{}", e.getEmployeeNo() + "的工资->" + totalAmount + ",执行顺序->A"); //汇总总工资 totalSalary.addAndGet(totalAmount); try { //等待其他线程同步 cyclicBarrier.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } return totalAmount; } }); } //执行顺序-A/B(之前或之后随机,totalSalary值不能保证一定会得到,所以CyclicBarrier更适合无返回的可重复并行计算) //封装响应参数 StatisticReportBO statisticReportBO = StatisticReportBO.builder().employeeCount(employeeSalaryInfos.size()) .departmentNo(statisticReportDTO.getDepartmentNo()) .salaryTotalAmount(totalSalary.get()).build(); log.info("封装接口响应参数,执行顺序->A/B"); return statisticReportBO; } @Data public static class EmployeeSalaryInfo { /** * 员工编号 */ private String employeeNo; /** * 基本工资 */ private Integer baseSalaryAmount; /** * 补助金额 */ private Integer subsidyAmount; } }上述代码的执行结果如下:
[kPoolExecutor-1] c.w.c.s.impl.SalaryStatisticServiceImpl : 计算出员工100的工资->13000,执行顺序- [kPoolExecutor-2] c.w.c.s.impl.SalaryStatisticServiceImpl : 计算出员工101的工资->33000,执行顺序- [kPoolExecutor-2] c.w.c.s.impl.SalaryStatisticServiceImpl : 汇总已分别计算出的两个员工的工资->46000, [nio-8080-exec-2] c.w.c.s.impl.SalaryStatisticServiceImpl : 封装接口响应参数,执行顺序->A/B
从上述结果可以看出,受CycliBarrier控制的线程会等待其他线程执行完成后同步向后执行,并且CycliBarrier并不会阻塞主线程,所以最后响应参数封装代码可能在CycliBarrier汇总线程之前执行,也可能在其之后执行,使用时需要注意!
Semaphore(信号量)限制访问资源的线程数
Semaphore可以实现对某个共享资源访问线程数的限制,实现限流功能。以停车场线程为例,代码如下:
@Service @Slf4j public class ParkServiceImpl implements ParkService { /** * 模拟停车场的车位数 */ private static Semaphore semaphore = new Semaphore(2); @Override public AccessParkBO accessPark(AccessParkDTO accessParkDTO) { AsyncManager.service.execute(() -> { if (semaphore.availablePermits() == 0) { log.info(Thread.currentThread().getName() + ",车牌号->" + accessParkDTO.getCarNo() + ",车位不足请耐心等待"); } else { try { //获取令牌尝试进入停车场 semaphore.acquire(); log.info(Thread.currentThread().getName() + ",车牌号->" + accessParkDTO.getCarNo() + ",成功进入停车场"); //模拟车辆在停车场停留的时间(30秒) Thread.sleep(30000); //释放令牌,腾出停车场车位 semaphore.release(); log.info(Thread.currentThread().getName() + ",车牌号->" + accessParkDTO.getCarNo() + ",驶出停车场"); } catch (InterruptedException e) { e.printStackTrace(); } } }); //封装返回信息 return AccessParkBO.builder().carNo(accessParkDTO.getCarNo()) .currentPositionCount(semaphore.availablePermits()) .isPermitAccess(semaphore.availablePermits() > 0 ? true : false).build(); } }上述代码模拟停车场有2车位,并且每辆车进入车场后会停留30秒,然后并行模拟3次停车请求,具体执行效果如下:
[kPoolExecutor-1] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-1,车牌号->10,成功进入停车场 顺序->A [kPoolExecutor-2] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-2,车牌号->20,成功进入停车场 顺序->A [kPoolExecutor-3] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-3,车牌号->30,车位不足请耐心等待00,执行顺序->B [kPoolExecutor-1] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-1,车牌号->10,驶出停车场 [kPoolExecutor-2] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-2,车牌号->20,驶出停车场 [kPoolExecutor-4] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-4,车牌号->30,成功进入停车场
可以看到由于通过Semaphore限制了可允许进入的线程数是2个,所以第三次请求会被拒绝,直到前两次请求通过.release()方法释放证书后第4次请求才会被允许进入!
后记
本文从应用层面总结了,JVM基本的内存模型以及线程对共享内存操作的原子方式,并着重介绍了线程池、FutrueTask、CountDownLatch、CycliBarrier以及Semaphore这几种在Java并发编程中经常使用的JUC工具类。

