您可能听说过瑞士军刀。如果没有,请看下面的图片。它包含许多刀片和工具。每个人都专门从事一项特定的任务。在某些情况下,不同的刀片可以完成相同的任务,但性能不同。

> Image by PublicDomainPictures from Pixabay
我将机器学习算法视为瑞士军刀。 有许多不同的算法。 某些任务需要使用特定的算法,而某些任务可以使用许多不同的算法来完成。 性能可能会根据任务和数据的特征而变化。
在本文中,我将分享16个技巧,我认为这些技巧将帮助您更好地理解算法。 我的目的不是要详细解释算法如何工作。 我宁愿提供一些有关它们的提示或细节。
一些技巧将更笼统,而不是针对特定算法。 例如,对数损失是与所有分类算法相关的成本函数。
我假设您对算法有基本的了解。 即使您不这样做,也可以选择一些详细信息,以便日后使用。
开始吧。
1.支持向量机(SVM)的C参数
SVM的C参数为每个错误分类的数据点增加了代价。如果c小,则对错误分类的点的惩罚较低,因此以较大数量的错误分类为代价选择了具有较大余量的决策边界。
如果c大,由于高罚分,SVM会尝试最大程度地减少误分类示例的数量,从而导致决策边界的边距较小。对于所有错误分类的示例,惩罚都不相同。它与到决策边界的距离成正比。
2.具有RBF内核的SVM的Gamma参数
具有RBF内核的SVM的Gamma参数控制单个训练点的影响距离。 较低的gamma值表示相似半径较大,这导致将更多点组合在一起。
对于较高的伽玛值,这些点必须彼此非常接近,以便在同一组(或类)中考虑。因此,具有非常大的伽玛值的模型往往会过拟合。
3.是什么使逻辑回归成为线性模型
逻辑回归的基础是逻辑函数,也称为Sigmoid函数,该函数接受任何实数值,并将其映射到0到1之间的一个值。
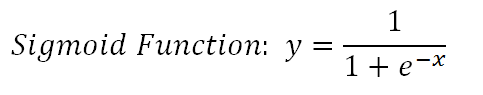
> (image by author)
它是一个非线性函数,但逻辑回归是一个线性模型。
这是我们从S型函数得到线性方程的方法:
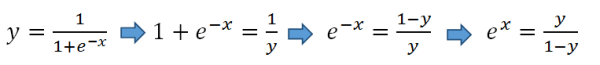
> (image by author)
以双方的自然对数:
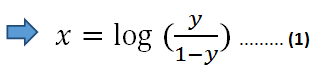
> (image by author)
在方程式(1)中,我们可以使用线性方程式z代替x:
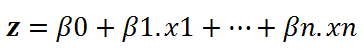
> (image by author)
然后,等式(1)变为:
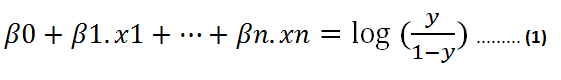
> (image by author)
假设y为正分类的概率。 如果为0.5,则上式的右侧变为0。
我们现在有一个线性方程要求解。
4. PCA中的主要组成部分
PCA(主成分分析)是一种线性降维算法。 PCA的目标是在减少数据集的维数(要素数量)的同时保留尽可能多的信息。
信息量由方差衡量。具有高方差的特征会告诉我们有关数据的更多信息。
主要成分是原始数据集特征的线性组合。
5.随机森林
随机森林是使用称为装袋的方法构建的,其中将每个决策树用作并行估计器。
随机森林的成功很大程度上取决于使用不相关的决策树。 如果我们使用相同或非常相似的树,则总体结果将与单个决策树的结果相差无几。 随机森林通过自举和特征随机性来实现具有不相关的决策树。
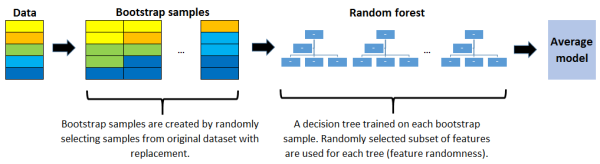
> (image by author)
6.梯度增强决策树(GBDT)
GBDT使用提升方法来组合各个决策树。 增强意味着将一系列学习算法串联起来,以从许多顺序连接的弱学习者中获得强大的学习者。
每棵树都适合前一棵树的残差。 与装袋不同,加强不涉及自举采样。 每次添加新树时,它都适合初始数据集的修改版本。
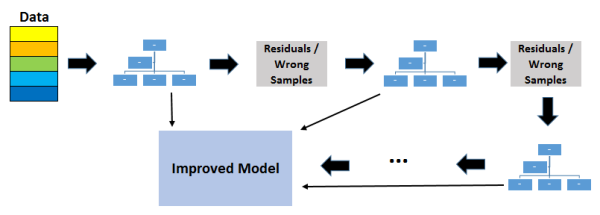
> (image by author)
7.增加随机森林和GBDT中的树的数量
增加随机森林中的树的数量不会导致过度拟合。 在某一点之后,模型的准确性不会因添加更多树而增加,但也不会因添加过多树而受到负面影响。 由于计算原因,您仍然不想添加不必要的树,但是不存在与随机森林中的树数相关联的过拟合风险。
但是,就过度拟合而言,梯度增强决策树中的树数非常关键。添加过多的树会导致过拟合,因此一定要停止添加树,这一点很重要。
8.层次聚类vs K-均值聚类
分层群集不需要预先指定群集数量。必须为k均值算法指定簇数。
它总是生成相同的聚类,而k均值聚类可能会导致不同的聚类,具体取决于质心(聚类中心)的启动方式。
与k均值相比,分层聚类是一种较慢的算法。特别是对于大型数据集,运行需要很长时间。
9. DBSCAN算法的两个关键参数
DBSCAN是一种聚类算法,可与任意形状的聚类一起很好地工作。这也是检测异常值的有效算法。
DBSCAN的两个关键参数:
eps:指定邻域的距离。 如果两个点之间的距离小于或等于eps,则将其视为相邻点。
minPts:定义集群的最小数据点数。
10. DBSCAN算法中的三种不同类型的点
根据eps和minPts参数,将点分为核心点,边界点或离群值:
· 核心点:如果在其半径为eps的周围区域中至少有minPts个点(包括该点本身),则该点为核心点。
· 边界点:如果一个点可以从核心点到达并且其周围区域内的点数少于minPts,则它是边界点。
· 离群点:如果一个点不是核心点并且无法从任何核心点到达,则该点就是离群点。
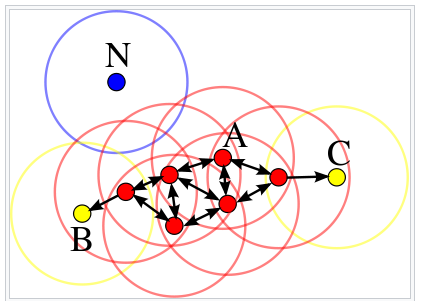
> Figure source
在这种情况下,minPts为4。红色点是核心点,因为在其周围区域内至少有4个半径为eps的点。 该区域在图中用圆圈显示。 黄色点是边界点,因为它们可以从核心点到达并且在其邻域内不到4个点。 可到达意味着在核心点的周围。 点B和C在其邻域内(即半径为eps的周围区域)有两个点(包括点本身)。 最后,N是一个离群值,因为它不是核心点,无法从核心点获得。
11.为什么朴素贝叶斯被称为朴素?
朴素贝叶斯算法假设要素彼此独立,要素之间没有关联。 但是,现实生活中并非如此。 特征不相关的这种朴素假设是将该算法称为"天真"的原因。
与复杂算法相比,所有特征都是独立的这一假设使朴素贝叶斯算法非常快。在某些情况下,速度比精度更高。
它适用于高维数据,例如文本分类,电子邮件垃圾邮件检测。
12.什么是对数损失?
对数损失(即交叉熵损失)是机器学习和深度学习模型广泛使用的成本函数。
交叉熵量化了两种概率分布得比较。 在监督学习任务中,我们有一个我们要预测的目标变量。 使用交叉熵比较目标变量的实际分布和我们的预测。 结果是交叉熵损失,也称为对数损失。
13.如何计算对数损失?
对于每个预测,都会计算真实类别的预测概率的负自然对数。所有这些值的总和使我们损失了对数。
这是一个可以更好地解释计算的示例。
我们有4个类别的分类问题。 我们针对特定观测值的模型的预测如下:
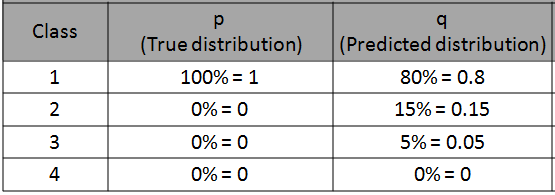
> (image by author)
来自此特定观察值(即数据点或行)的对数损失为-log(0.8)= 0.223。
14.为什么我们使用对数损失而不是分类准确性?
在计算对数损失时,我们采用预测概率的自然对数的负数。我们对预测的确定性越高,对数损失就越低(假设预测正确)。
例如,-log(0.9)等于0.10536,-log(0.8)等于0.22314。因此,确定为90%比确定为80%所导致的日志损失更低。
分类,准确性和召回率等传统指标通过比较预测的类别和实际类别来评估性能。
下表显示了在由5个观测值组成的相对较小的集合上两个不同模型的预测。
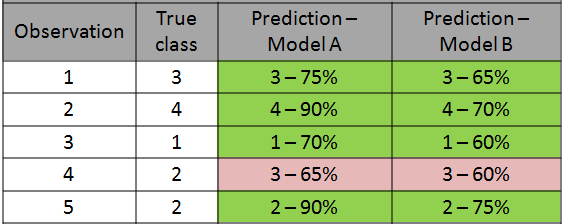
> (image by author)
两种模型都正确地将5个观测值归为5个。因此,就分类精度而言,这些模型具有相同的性能。但是,概率表明模型1在预测中更为确定。因此,总体上可能会表现更好。
对数损失(即交叉熵损失)提供了对分类模型的更强大和准确的评估。
15. ROC曲线和AUC
ROC曲线通过组合所有阈值处的混淆矩阵来总结性能。 AUC将ROC曲线转化为二进制分类器性能的数字表示。 AUC是ROC曲线下的面积,取值介于0到1之间。AUC表示模型在分离阳性和阴性类别方面的成功程度。
16.精度度和召回率
精度度和召回率指标使分类精度进一步提高,使我们对模型评估有了更具体的了解。 首选哪一个取决于任务和我们要实现的目标。
精度衡量的是当预测为正时我们的模型有多好。精度的重点是积极的预测。它表明有多少积极预测是正确的。
回忆度量了我们的模型在正确预测肯定类别方面的表现。 召回的重点是实际的正面课堂。 它指示模型能够正确预测多少个肯定类别。
结论
我们已经涵盖了一些基本信息以及有关机器学习算法的一些细节。
有些要点与多种算法有关,例如关于对数损失的算法。 这些也很重要,因为评估模型与实施模型同等重要。
所有机器学习算法在某些任务中都是有用且高效的。根据您正在执行的任务,您可以精通其中的一些。
但是,了解每种算法的工作原理很有价值。

