公司最近安排了一波商品抢购活动,由于后台小哥操作失误最终导致活动效果差,被用户和代理商投诉了。经理让我带同事们一起复盘这次线上事故。
图片来自 Pexels
什么原因造成的?
抢购活动计划是零点准时开始:
22:00,运营人员通过后台将商品上线。
23:00,后台小哥已经将商品导入缓存中,提前预热。
抢购开始的瞬间流量非常大,按计划是通过 Redis 承担大部分用户查询请求,避免请求全部落在数据库上。
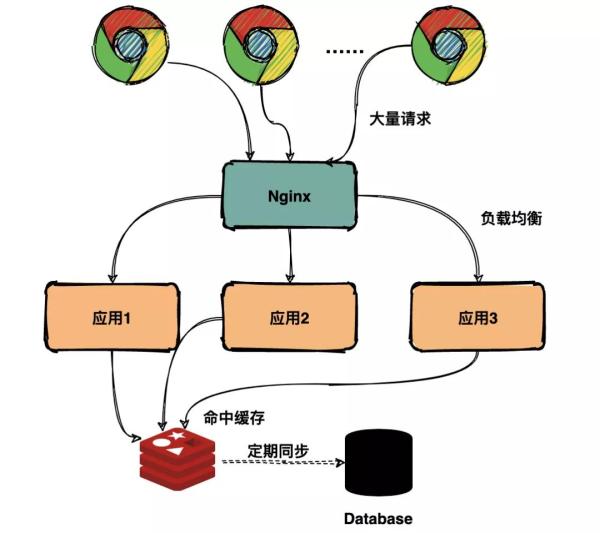
缓存命中
如上图预期大部分请求会命中缓存,但是由于后台小哥预热缓存的时候将所有商品的缓存时间都设置为 2 小时过期。
因此所有的商品在同一个时间点全部失效,瞬间所有的请求都落在数据库上,导致数据库扛不住压力崩溃,用户所有的请求都超时报错。
实际上所有的请求都直接落到数据库,如下图:
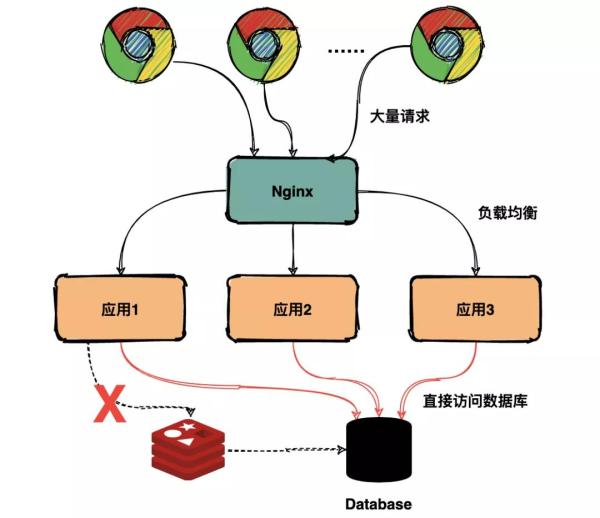
缓存雪崩
什么时候发现的?
凌晨 01:02,SRE 收到系统告警,登录运维管理系统发现数据库节点 CPU 和内存飙升超过阈值,迅速联系后台开发人员定位排查。
为什么没有早点发现?
由于缓存设置过期时间是 2 小时,凌晨 1 点前缓存可以命中大部分请求,数据库服务处于正常状态。
发现时采取了什么措施?
后台小哥通过日志定位排查发现问题后,进行了一系列操作:
首先通过 API Gateway(网关)限制大部分流量进来。
接着将宕机的数据库服务重启。
再重新预热缓存。
确认缓存和数据库服务正常后将网关流量正常放开,大约 01:30 抢购活动恢复正常。
如何避免下次出现?
这次事故的原因其实就是出现了缓存雪崩,查询数据量巨大,请求直接落到数据库上,引起数据库压力过大宕机。
在业界解决缓存雪崩的方法其实比较成熟了,比如有:
均匀过期
加互斥锁
缓存永不过期
均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
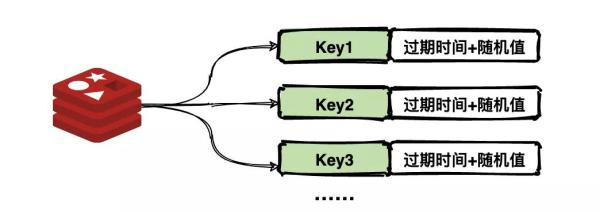
缓存 key 过期时间均匀分布
加互斥锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
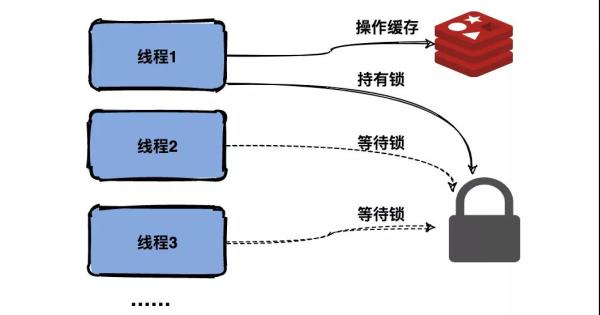
互斥访问
缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
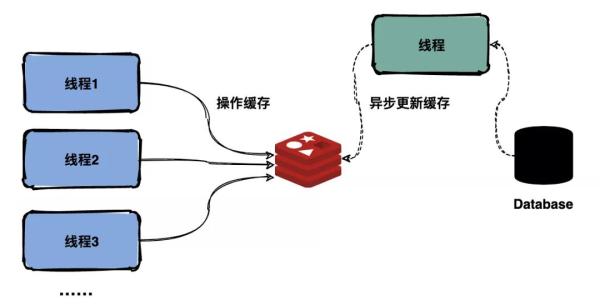
异步更新缓存
复盘总结
通过与同事复盘这次线上事故,大家对于缓存雪崩有了更深刻的理解。
为了避免再次出现缓存雪崩事故,大家一起讨论了多个解决方案:
均匀过期
加互斥锁
缓存永不过期
希望技术人能够敬畏每一行代码!
作者:雷架,华中科技大学硕士毕业;浪过几个大厂:华为、网易、百度……
编辑:陶家龙
出处:转载自公众号爱笑的架构师(ID:DancingOnYourCode)

