近日,谷歌宣布将 AI 语言模型 ELECTRA 作为 TensorFlow 之上的开源模型发布。该方法用到了一种称为替换令牌检测(RTD)的新预训练任务,使其能够在从所有输入位置学习的同时,训练双向模型。
并且,在同等计算资源的情况下,ELECTRA 的性能优于现有方法;而在参数量只有 1/30 的情况下,取得不逊于最先进 BERT 系列模型的性能。谷歌发布了相关文章介绍这一开源成果,雷锋网 AI 源创评论将其整理编译如下。

语言模型现状与瓶颈
近年来,语言预训练模型的最新进展使得自然语言处理也取得了重大进展,其中不乏一些最先进的模型,例如:BERT,RoBERTa,XLNet,ALBERT 和 T5 等。
这些方法虽然在设计上有所不同,但在利用特定的 NLP 任务(例如:情感分析和问题解答等)进行微调时,有着相同思路,即:利用大量未标记的文本,来构建语言理解的通用模型。
因此,现有的预训练方法通常分为两类:语言模型(LM),例如:GPT。该类方法按照从左到右的顺序处理输入文本,然后在给定先前上下文的情况下,预测下一个单词。
另一个则是掩码语言模型(MLM),例如:BERT,RoBERTa 和 ALBERT。这类模型它们分别预测输入中已被屏蔽的少量单词内容。MLM 相比 LM 而言,具有双向预测的优势,因为它可以看到要预测的单词左侧和右侧的文本。
但 MLM 模型预测也有缺点,这些模型的预测仅限于输入标记的某个很小的子集(被掩盖部分的 15%),从而减少了他们从每个句子中获得信息的量,增加了计算成本。
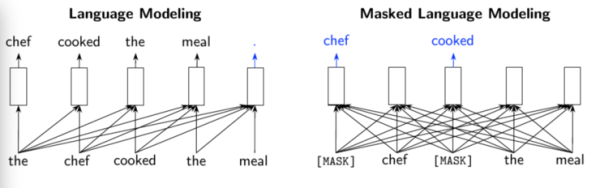

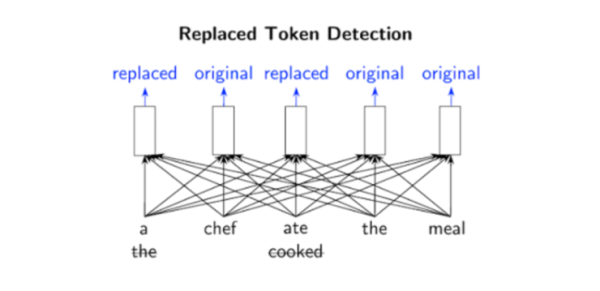 从所有输入位置学习时,替换的令牌检测可进行双向训练
从所有输入位置学习时,替换的令牌检测可进行双向训练
其中,替换令牌来自生成器的神经网络。生成器的目标是训练掩码语言模型,即给定输入序列后,按照一定的比例(通常 15%)将输入中的词替换成掩码;然后通过网络得到向量表示;之后再采用 softmax 层,来预测输入序列中掩盖位置的词。
尽管生成器的结构类似于 GAN,但由于难以将该方法应用于文本任务,因此得到的训练目标函数为掩盖词的最大似然。
之后,生成器和判别器共享相同的输入词嵌入。判别器的目标是判断输入序列每个位置的词是否被生成器替换,如果与原始输入序列对应位置的词不相同,就判别为已替换。
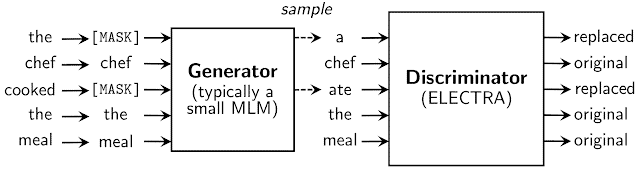 生成器与判别器神经网络模型
生成器与判别器神经网络模型
具体研究结果对比
研究人员将 ELECTRA 与其他最新的 NLP 模型进行了比较,发现在给定相同的计算预算的情况下,它与以前的方法相比有了实质性的改进,其性能与 RoBERTa 和 XLNet 相当,而使用的计算量不到 1/4。
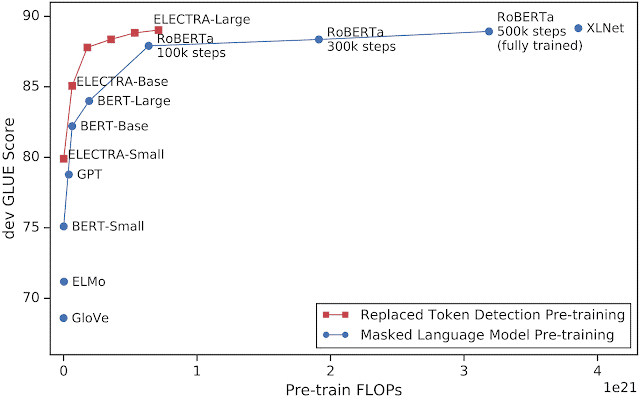
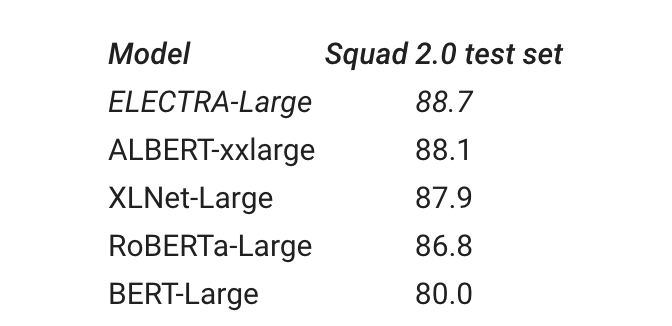 SQUAD 2.0 数据集在 ELECTRA-Large 和其他最新模型中得分
SQUAD 2.0 数据集在 ELECTRA-Large 和其他最新模型中得分
目前,用于预训练 ELECTRA 并在下游任务上对其进行微调的代码已发布,当前支持的任务包括:文本分类、问题解答和序列标记。
该代码支持在一个 GPU 上快速训练小型 ELECTRA 模型。之后,谷歌还计划发布适用于 ELECTRA-Large,ELECTRA-Base 和 ELECTRA-Small 的预训练代码。(ELECTRA 模型目前仅支持英语,后续将发布更多语言版本)转载自雷锋网。
原文地址:
https://ai.googleblog.com/2020/03/more-efficient-nlp-model-pre-training.html
GitHub 地址:
https://github.com/google-research/electra

