8.用于语义角色标注的语言学信息自我注意力方法,作者:EMMA STRUBELL,PATRICK VERGA,DANIEL ANDOR,DAVID WEISS,ANDREW MCCALLUM
论文摘要
当前最先进的语义角色标记(SRL)使用深度神经网络,但没有明确的语言特征。之前的工作表明,抽象语法树可以显著改善SRL,从而提高模型准确性。在这项研究中,我们提出了语言学的自我关注(LISA):该神经网络模型将 multi-head self-attention 与多任务学习相结合,包括依赖解析、词性标注、谓词检测和语义角色标记。与先前需要大量预处理来准备语言特征的模型不同,LISA 可以仅使用原始的 token 对序列进行一次编码,来同时执行多个预测任务。此外,如果已经有高质量的语法分析,则可以在测试时加入,而无需重新训练我们的SRL模型。在CoNLL-2005 SRL的实验中,LISA使用预测谓词和标准字嵌入帮助模型实现了最新的最先进性能。LISA还通过上下文编码(ELMo)词表示超出了最新技术水平。
总结
来自UMass Amherst信息与计算机科学学院和Google AI语言的研究人员介绍了基于语言学的自我注意(LISA),这是一种结合了深度学习和语言形式主义的神经网络模型,因此它能够更有效地利用句法解析来获得语义。实验表明,LISA不仅在新闻领域应用表现优秀,它还在分析写作风格方面取得了最先进的表现,而且还可以很好地概括在不同领域的写作风格,如新闻和小说写作。
论文的核心思想是什么?
· 基于Transformer编码器的语言学自我关注(LISA)模型。
· 网络的输入可以是一系列标准的预训练GloVe字嵌入,但是通过预先训练的ELMo表示与任务特定的学习参数相结合,可以实现更好的性能。
· 为了将语言知识传递到后面的层次,研究人员建议训练自我关注机制以处理与句子的句法结构相对应的特定标记。此外,可以在测试时执行辅助解析信息的注入,而无需重新训练模型。
· 遵循多任务学习方法,共享语义角色标记(SRL)模型中较低层的参数以预测词性和谓词。
取得了什么关键成就?
· 开发一种将语法集成到神经网络模型中的新技术。
· 在语义角色标记中实现最新的最先进性能:
1、使用GloVe嵌入:在新闻领域上获得+2.5 F1积分,在域外文本上获得+ 3.5F1分数;
2、使用ELMo嵌入:在新闻上获得+1.0 F1点,在域外文本上获得+2.0F1分数。
AI社区对其评价是什么?
1.该论文被EMNLP 2018评为最佳长篇论文奖,EMNLP 2018是自然语言处理领域的领先会议。
未来的研究领域是什么?
· 提高模型的解析精度。
· 开发更好的训练技巧。
· 适应更多任务。
什么是可能的商业应用?
1、语义角色标记对许多下游NLP任务很重要,包括:
§ 信息提取;
§ 问题回答;
§ 自动摘要;
§ 机器翻译。
你在哪里可以得到实现代码?
1.本研究论文的实施可从这里获得。
9.一种用于学习语义任务嵌入的分层多任务方法,作者:VICTOR SANH,THOMAS WOLF和SEBASTIAN RUDER
论文摘要
我们已经投入了大量精力来评估是否可以利用多任务学习在各种自然语言处理的应用中使用丰富表示。然而,我们真正缺乏的是对多任务学习具有显著影响的设置的理解。在这篇论文中,我们介绍了在一个精心挑选在多任务学习设置中训练的分层模型。该模型以分层方式进行训练,通过监督模型底层的一组低级任务和模型顶层的更复杂任务来归纳偏差。该模型在许多任务上实现了最优秀的结果,例如命名实体识别。分层训练监督在模型的较低层引入一组共享语义表示,我们已经证实,当我们从模型的底层移动到顶层时,层的隐藏状态往往代表更复杂的语义信息。
总结
研究人员为一组相互关联的NLP任务引入了一种多任务学习方法:命名实体识别,实体指代识别,共指消解和关系提取。他们证实,以分层方式训练的单一模型可以解决上述的四项任务。此外,与单任务模型相比,多任务学习框架显着加快了训练过程。
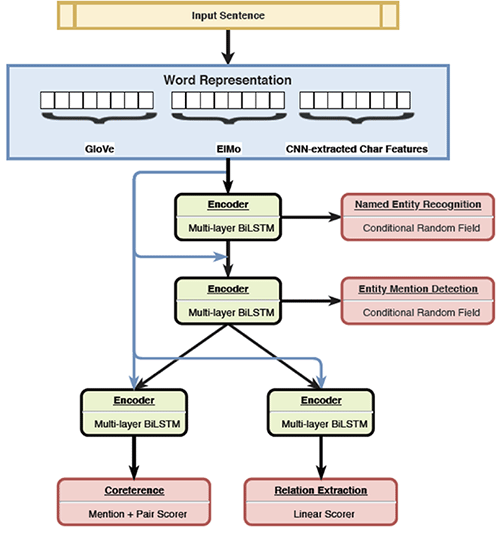
本文的核心思想是什么?
· 多任务学习方法可以有效地用于一组相互依赖的NLP任务。
· 四个基本语义NLP任务:命名实体识别,实体指代识别,共指消解和关系提取相互受益,因此可以组合在单个模型中。
· 该模型假定所选语义任务之间存在层次结构:某些任务更简单,需要对输入进行较少的修改,因此可以在神经网络的较低层进行监督学习,而其他任务则更加困难,需要更复杂的处理输入,因此,应该在神经网络的更高层监督学习。
什么是关键成就?
· 分层多任务学习模型(HMTL)在4个任务中的挑战了其中三个最先进的结果,即命名实体识别,关系提取和实体指代检测任务。
· 与单任务模型相比,多任务学习框架大大加快了训练速度。
AI社区对其的看法是什么?
1.该论文将在2019年1月的AAAI会议上发表。
未来的研究领域方向是什么?
· 将多任务学习模型与预训练的BERT编码器相结合。
· 搜索多任务学习的其他设置。
什么是可能的商业应用?
1、企业可以利用这种多任务学习方法的优势,即高性能和高训练速度,来增强:
§ 聊天机器人和语音助理的表现;
§ 在文件中查找相关信息;
§ 分析客户评论等;
你在哪里可以得到实现代码?
1.你可以在GitHub上的获得这篇研究论文的代码。
10. 了解你不知道的事情:SRANAD的无法回答的问题,作者:PRANAV RAJPURKAR,ROBIN JIA和PERCY LIANG
论文摘要
提取阅读理解系统通常可以在上下文文档中找到问题的正确答案,但是它们也倾向于对在上下文中没有陈述正确答案的问题做出不可靠的猜测。现有数据集太专注于可回答的问题,为了解决这些弱点,我们提供了SQuAD 2.0,这是斯坦福问答数据集(SQuAD)的最新版本。SQuAD 2.0将现有的SQuAD数据与众包工作者写的50000多个无法回答的问题结合起来,看起来类似于可回答的问题。为了在SQuAD 2.0上做得好,系统不仅要在可能的情况下回答问题,还要确定段落何时不支持答案并且不回答问题。
总结
斯坦福大学的一个研究小组扩展了著名的斯坦福问答数据集(SQUAD),增加了超过5万个个无法回答的问题。这些问题的答案无法在段落中找到,但问题与可回答的问题非常相似。更重要的是,段落包含对这些问题的合理(但不正确)答案。这使得新的SQuAD 2.0对现有的最先进模型极具挑战性:在引入无法回答的问题之后,一个强大的神经系统在之前版本的SQuAD上达到86%的准确率,而现在只有66%。

本文的核心思想是什么?
· 当前的自然语言理解(NLU)系统远非真正的语言理解,其中一个根本原因是现有的Q&A数据集关注的是在上下文文档中保证正确答案存在的问题。
· 要真正具有挑战性,应该创建无法回答的问题,其中:
§ 它们与支持段落相关;
§ 该段包含一个似是而非的答案,其中包含与问题要求相同类型的信息,但不正确。
什么是关键成就?
· 通过53777个新的无法回答的问题扩展SQuAD,从而构建具有挑战性的大规模数据集,迫使NLU系统学习何时无法根据上下文回答问题。
· 通过显示现有模型66%的准确性,为NLU系统创造新的挑战。
· 显示合理的答案确实可以作为NLU系统的有效干扰者。
AI社区对其的看法是什么?
· 该论文被2018年计算语言学协会(ACL)公布为最佳短篇论文。
· 新的数据集增加了NLU领域的复杂性,实际上可以为该研究领域带来巨大的绩效训练。
未来的研究领域是什么?
1.开发“知道他们不知道的东西”的新模型,从而更好地理解自然语言。
可能的商业应用是什么?
1.在这个新数据集上训练阅读理解模型应该可以提高他们在现实情况下的表现,而这些情景往往无法直接获得答案。
你在哪里可以得到实现代码?
1.该官方标准队内网站有训练数据集和比较表现最出色的训练排行榜。
文章原标题《WE SUMMARIZED 14 NLP RESEARCH BREAKTHROUGHS YOU CAN APPLY TO YOUR BUSINESS》作者:Mariya Yao
译者:虎说八道,审校:袁虎。

