最近,一些 AI 生成视觉形象的应用爆火,例如只需 9 块 9 就能生成个人写真的「妙鸭相机」。由于操作简单,不涉及任何技术操作,很多用户都纷纷在朋友圈晒出妙鸭相机生成的写真。
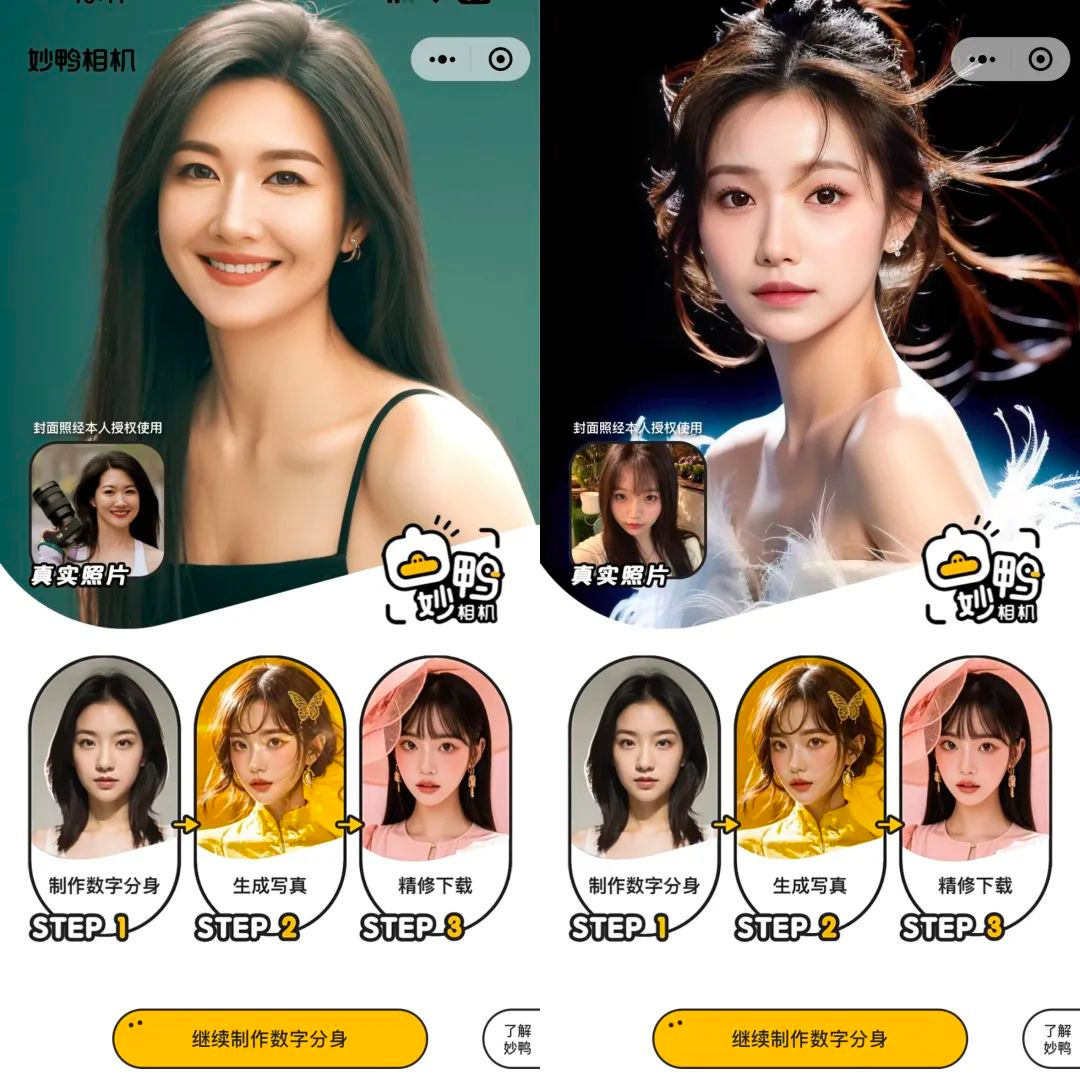
妙鸭相机虽然好用,但它是一个需要付费的应用。现在,一个名为 FaceChain 的开源项目可以用 AI 模型打造人物写真。项目上线一周,已经狂揽 2.5k star,今天还上了Github趋势排行榜第一名。
项目地址:https://github.com/modelscope/facechain
用户仅需提供最低三张照片,就可以获得特定风格的个人写真。例如,生成商务证件照:

也可以在 ModelScope 创空间中直接体验这项应用,无需任何安装步骤。

试玩地址:https://modelscope.cn/studios/CVstudio/cv_human_portrait/summary


作者在项目介绍中讲解了 AI 生成个人写真的技术原理,解释了生成式 AI 模型如何成为「写真神器」,我们来看下这部分讲解内容。
个人写真的生成原理
基本原理
AI 生成个人写真的能力来源于 Stable Diffusion 模型的文生图功能,—— 输入一段文本或一系列 prompt,输出对应的图像。而影响个人写真生成效果的因素主要有两方面:写真风格信息和用户人物信息。
为此,项目作者分别使用线下训练的风格 LoRA 模型和线上训练的人脸 LoRA 模型来学习上述两方面的信息。LoRA 是一种具有较少可训练参数的微调模型,在 Stable Diffusion 中,可以通过对少量输入图像进行文生图训练的方式将输入图像的信息注入到 LoRA 模型中。
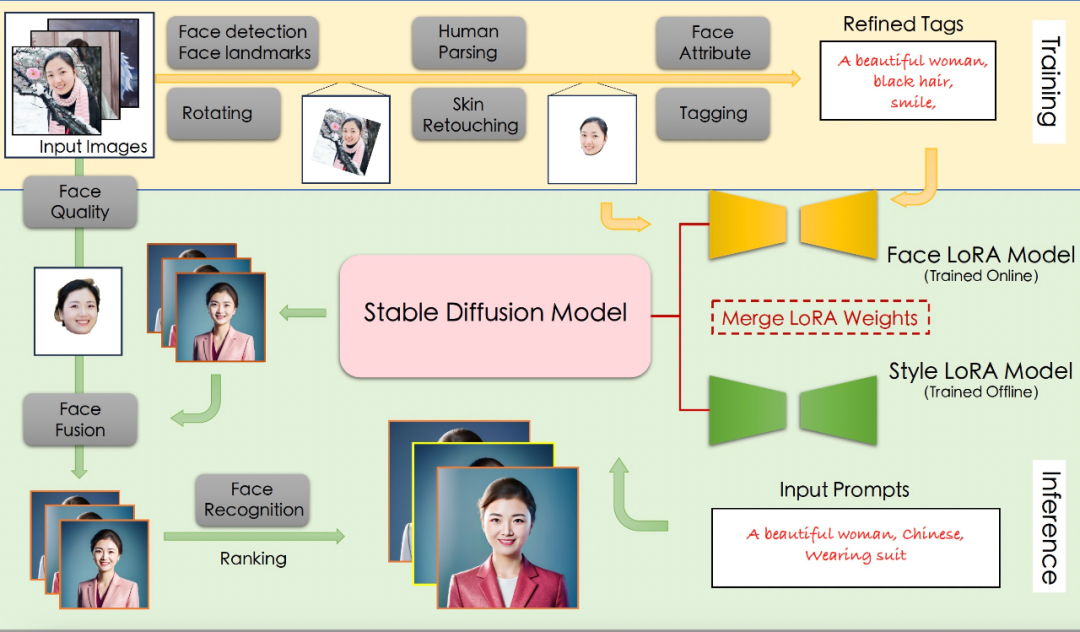
因此,个人写真模型的能力分为训练与推断两个阶段,训练阶段生成用于微调 Stable Diffusion 模型的图像与文本标签数据,得到人脸 LoRA 模型;推断阶段基于人脸 LoRA 模型和风格 LoRA 模型生成个人写真图像。
训练阶段
训练阶段的输入是用户上传的包含清晰人脸区域的图像,输出是人脸 LoRA 模型。
具体来说,项目作者首先使用基于朝向判断的图像旋转模型,以及基于人脸检测和关键点模型的人脸精细化旋转方法,来处理用户上传图像,得到包含正向人脸的图像;接下来使用人体解析模型和人像美肤模型,以获得高质量的人脸训练图像;随后,该项目使用人脸属性模型和文本标注模型,结合标签后处理方法,产生训练图像的精细化标签;最后使用上述图像和标签数据微调 Stable Diffusion 模型得到人脸 LoRA 模型。
推断阶段
推断阶段的输入是训练阶段用户上传图像和预设的用于生成个人写真的输入 prompt,输出是个人写真图像。
在推断阶段,该项目首先将人脸 LoRA 模型和风格 LoRA 模型的权重融合到 Stable Diffusion 模型中;接下来使用 Stable Diffusion 模型的文生图功能,基于预设的 prompt 初步生成个人写真图像;随后,该项目使用人脸融合模型进一步改善上述写真图像的人脸细节,其中用于融合的模板人脸通过人脸质量评估模型在训练图像中进行挑选;最后再使用人脸识别模型计算生成的写真图像与模板人脸的相似度,以此对写真图像进行排序,并输出排名靠前的个人写真图像作为最终输出结果。
项目作者已详细介绍安装与使用方法,并将项目代码开源,感兴趣的读者快去试试吧。

