BERT 是 Google 去年发布的自然语言处理模型,它在问答系统、自然语言推理和释义检测(paraphrase detection)等任务中取得了突破性的进展。由于 BERT 是公开可用的,它在研究社区中很受欢迎。BERT 的全称是 Bidirectional Encoder Representation from Transformers,即双向 Transformer 的 Encoder。但是,在动态的商业环境中部署基于 Transformer 的大型模型 BERT,通常会产生较差的结果。这是因为商业环境通常是动态的,并且包含了推理和训练数据之间的连续域转换。Intel 人工智能实验室近日发表了一篇博文,阐述 BERT 在商用环境失败的原因以及解决对策。
本文最初发表在 Kdnuggets,经 Kdnuggets 官网授权,InfoQ 中文站翻译并分享。
基于 Transformer 的大型神经网络,如 BERT、GPT 和 XLNET,最近在许多自然语言处理任务取得了最先进的结果。这些模型之所以能够获得成功,得益于通用任务(如,语言建模)和特定下游任务之间的迁移学习。在有标记数据可用的静态评估集上,这些模型表现十分出色。然而,在动态的商业环境中,部署这些模型却通常会产生较差的结果。这是因为,商业环境通常是动态的,并且还包含推理和训练数据之间的连续域转换(例如,新主题、新词汇或新写作风格等)。
处理这些动态环境的传统方法是进行连续的再训练和验证,但这需要持续的手动数据标记,这既耗时,又昂贵,因此不切实际。在数据稀缺的商业环境中,有望实现更好的健壮性和可伸缩性的途径是,在微调阶段将与领域无关的知识嵌入预训练模型中。
预训练模型在低资源环境中表现出色
实际上,许多商业设置在多个领域中运行的是相同的任务。例如,考虑两种不同产品的情绪分析,如相机(领域 A)和笔记本电脑(领域 B),在这种情况下,用于不同领域的现有标记数据量通常很少,而且生成额外的标记数据既昂贵又不切实际。
与从头开始训练模型相比,预训练模型的一个主要优势在于,它们能够通过使用相对较少的标记数据来适应特定任务(见图 1)。这一优势在实际的多域环境中具有重要作用。
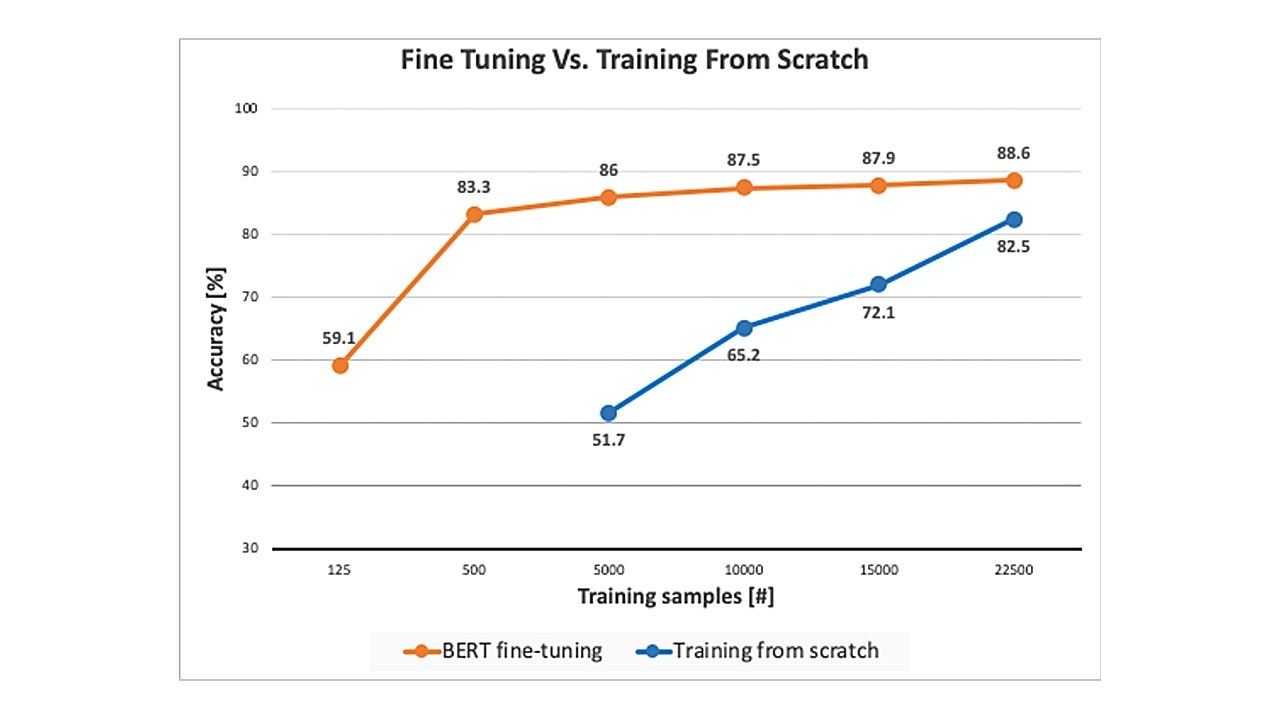
但是,是什么使这种经过微调的预训练模型的增强功能在地数据环境中获得成功呢?部分原因在于,在大规模的预训练步骤中,网络学习了句法等结构化语言特征。由于语法是一种通用特性,因此它既是任务无关的,也是领域无关的。这种通用的“知识”有助于弥合不同任务和领域之间的差距,并通过微调步骤加以利用,以提高数据效率。
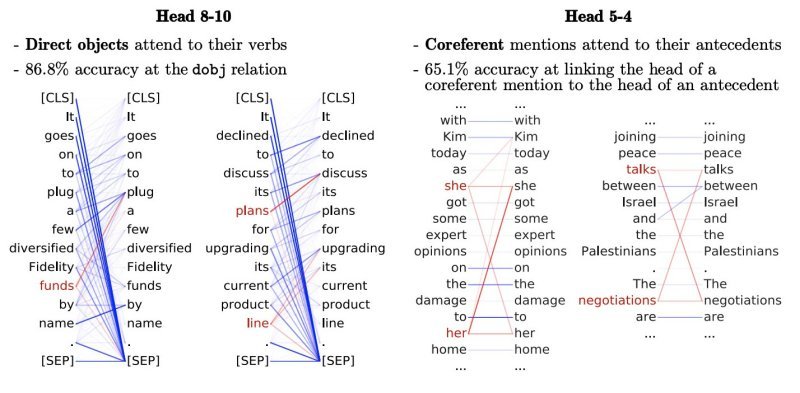
最近一篇题为《 BERT 在看什么?》(What Does BERT Look At?) 的文章,为人们了解 BERT 在预训练期间学到的东西提供了一些线索。通过对 BERT 的自注意力机制的分析,可以看出,BERT 学到了大量的语言知识。例如,BERT 的一些注意力头(attention-heads)注意了动词的直接宾语、名词的限定词,如定冠词,甚至还有共指指称(coreferent mention)(见图 2)。值得注意的是,一个以无监督学习的方式训练的模型,在没有任何标记数据的情况下,能够学习语言的通用方面的知识。
预训练模型能解决动态商业环境的挑战吗?
在一些动态的商业环境中,根本不可能会生成任何有标记的数据。请考虑这样一个环境,其中新域经常被添加或更改。在这种情况下,不断标记新的训练数据,将是一项无效、且永无止境的任务。这些情况需要无监督的域适应系统,该系统使用来自一个域(源域)的现有标记数据进行训练,然后对来自另一个域(目标域)的未标记数据进行推理。
我们观察到,预训练模型在有少量目标域标记数据的情况下表现出色,但在目标语没有任何标记数据的情况下,情况会如何呢?预训练模型在这些环境表现如何?到目前为止,使用预训练模型与从头开始的训练相比,只有很小的改进(见图 3 中的蓝线和橙线)。使用标记的目标域数据(绿色条)对 BERT 进行微调,与仅使用源域数据(蓝色条和橙色条)对 BERT 进行微调,或从头开始训练 RNN ,这三者之间的巨大差距表明,在预训练期间,预训练模型学习到的信息比从头开始的训练有所增强,但是,当目标域中的标记数据不可用时,仅仅进行跨域扩展还是不够的。或者更直截了当地说,无监督领域适应问题仍然远远不能通过仅使用源域数据的微调预训练模型来解决。

资料来源:Intel 人工智能实验室。配置:INtel Xeon E5-2600A v4 CPU @ 2.40GHz。Intel 于 2020 年 2 月 27 日完成测试。
缩小差距的一步:嵌入结构信息
那么,为了缩小域内环境和完全跨域环境之间的差距,我们可以做些什么呢?在 Yann LeCun 和 Christopher Manning 之间的公开讨论中,Manning 认为,与缺乏结构信息的系统相比,提供结构信息可以使我们设计出从较少的数据中学到更多信息的系统,并且具有更高的抽象级别。这一观点,得到了自然语言处理社区的广泛支持。
事实上,最近的一系列的研究表明,使用结构信息(即句法信息),可以改进泛化模型。这种改进的泛化增强了域内设置模型的健壮性,对于跨域设置更是如此。例如,在介绍 LISA(基于语言学的自注意力,Linguistically-Informed Self-Attention)模型的最新著作中,作者表明,在跨域设置中,嵌入句法依存解析信息可以显著提高 SRL 任务的正确性。作者将句法信息直接嵌入到 Transformer 网络的注意力头中,并从头开始进行训练。
最近的另一项研究表明,在完形填空测试任务中,使用依存关系和共指链作为辅助监督嵌入自注意力模型比最大的 GPT-2 模型表现得更好。其他研究表明,对共指消解(coreference resolution)和神经机器翻译(Neural Machine Translation,NMT)等任务具有更好的泛化能力。
最近的这些进步,使我们离在数据稀缺的商业环境中实现更好的健壮性和可伸缩性更近了一步,但仍然存在一些有待解决的问题和挑战,需要自然语言处理社区来解决。应该使用什么类型的外部信息?这些信息应该如何嵌入预训练模型?
结 语
大型基于 Transformer 的预训练模型最近在许多自然语言处理任务取得了最先进的结果。这些模型是为一般的语言建模任务而训练的,它们学习语言的一些基本结构特征,这些特征使它们能够更好地跨域泛化。当给定少量标记的目标域数据时,它们在跨域设置中表现得非常好。但是,处理没有标记的目标域数据的动态跨域设置的挑战仍然存在。在微调阶段,将外部领域无关的知识(即句法信息),嵌入到预训练模型中,有望在数据稀缺的商业环境中实现更好的健壮性和可伸缩性。
作者介绍:
Oren Pereg、Moshe Wasserblat 与 Daniel Korat,供职于 Intel 人工智能实验室。
原文链接:
https://www.kdnuggets.com/2020/03/bert-fails-commercial-environments.html


