什么时候能去武大看樱花?什么时候才能再去重庆吃麻辣火锅?什么时候才能再去海南冲浪?什么时候才能再去大理看风花雪月?2020年的春节显得格外漫长,一切的计划似乎都被突如其来的新冠肺炎疫情给打断了。

究竟什么时候生活才能恢复正常?本文将试图用python对疫情的趋势做个预测,待疫情结束之时,一起去武汉看樱花,一起去春熙路看小姐姐可好。
1.准备工作
编程环境:anaconda下Spyder。
数据来源:整理自国家卫生健康委员会官网。
需要安装的依赖库有:scipy。scipy是一个用于数学、科学等领域的开源科学计算库,其建立在Numpy之上,可用于处理积分、优化、常微分方程数值解的求解、信号处理等问题。本文主要用于函数拟合。
2.算法流程
1).理论解释
如何预测新冠肺炎的累计确诊人数,目前常用的方法有基于SIR的传染病模型,以及基于Logistic方程的方法等。SIR模型实现起来相对较复杂,本文将基于一个更简单的模型——利用Logistic方程进行预测。
Logistic方程可用于描述,物种增长模型,当一个物种迁入到一个新生态系统中后,若该物种在非理想生态系统(存在天敌,食物、空间等资源紧缺等)中存在生存阻力,则物种数量大致呈现S型增长。开始产生一个缓慢的增长期,慢慢的呈现指数型爆发,后期随着环境阻力的变化,逐渐趋于稳定。
用函数可以表示为:
参数的含义如下:
:表示随着时间的变化,环境中物种的数量。
:表示环境中物种能达到的极限值。
:表示环境开始时期,物种的数量。
:表示增长速率,在图形中展现的就是曲线的陡峭程度,越大,物种数量越快逼近N值。
:表示时间。
2).程序实现
程序中,首先定义待拟合函数,然后获取“累计确诊”人数数据,并利用curve_fit()函数进行参数拟合,得出需要拟合的参数。最后将拟合曲线和实际确诊人数在同一图中显示,直观观测出模型效果。



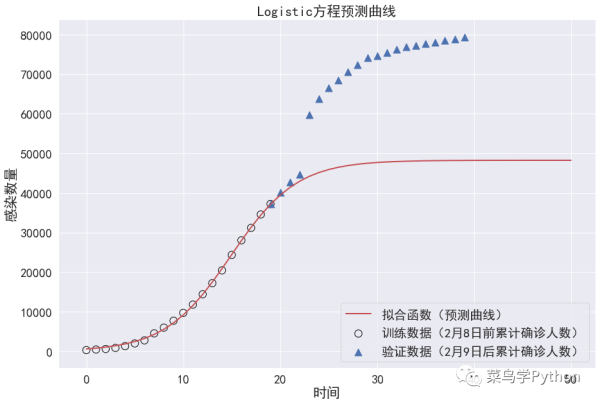
通过将1月20日至2月8日的数据进行Logistic方程拟合,在2月9-11日三天预测数据和实际数据较为吻合。但在2月12日,官方的数据突然激增,这让我们的模型失效。
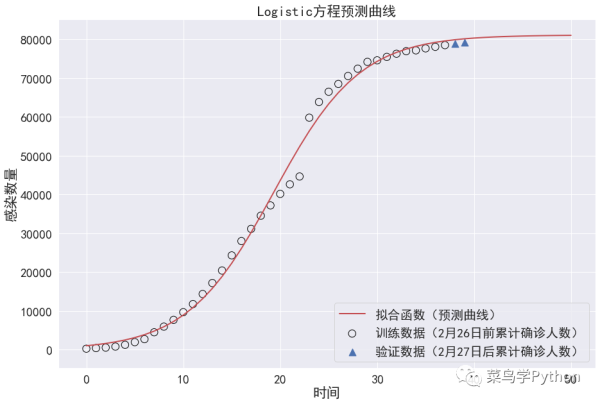
在重新调整训练数据,我们选择将1月20日至2月26日的数据作为训练数据,2月27-28日数据作为对照数据,可得到新的拟合曲线,预测值和实际值都相对较为吻合。
结论:
(1)利用Logistic方程进行预测的数据统计口径很关键,统计标准一致,可以让整个拟合曲线更为平滑。
(2)通过预测曲线预计累计确诊人数将在3月上旬达到最大值(预计为8万余人),之后疫情将逐渐趋于稳定。
休息了那么久,在疫情即将结束之际,也希望大家新的一年里,不要被疫情耽误,尽快进入工作。山花烂漫之时,一起去旅行。
(文章来源:菜鸟学python)


