


















像许多追随AI发展的人一样,我无法忽略生成建模的最新进展,尤其是图像生成中生成对抗网络(GAN)的巨大成功。看看下面这些样本:它们与真实照片几乎没有区别!

从2014年到2018年,面部生成的进展也非常显着。
这些结果让我感到兴奋,但我内心总是怀疑它们是否真的有用且广泛适用。基本上我“怀疑”,凭借生成模型的所有功能,我们并没有真正将它们用于比高分辨率面部表情生成这些更实用的东西。当然,有些企业可以直接基于图像生成或风格转移(如游戏行业中的角色生成或关卡生成,从真实照片到动漫头像的风格转换),但我一直在寻找GAN和其他生成方式更多领域模型的应用。我想通过生成模型,我们不仅可以生成图像,还可以生成文本、声音、音乐、结构化数据,如游戏关卡或药物分子。
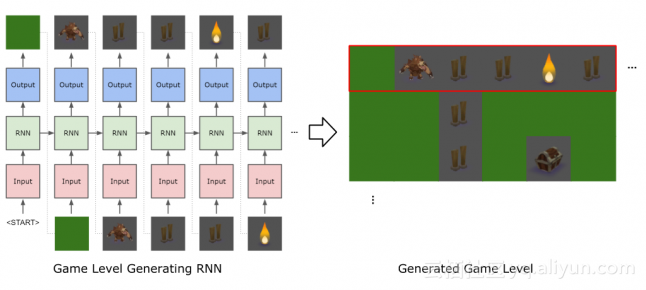
使用RNN生成游戏人物
在本文中,我将介绍7个用例。其中一些我已经亲自确认它们的用处,其他一些正在研究中,但这并不意味着它们不值得尝试。所有这些使用生成模型创建的例子都可以应用于不同的领域,因为我们的主要目标不是生成一些现实的东西,而是利用神经网络的内在知识来完成新任务。
1.数据增强
最明显的应用是训练模型:从我们的数据生成新样本以增强我们的数据集。我们如何检查这种增强是否真的有帮助呢?有两个主要策略:我们可以在“假”数据上训练我们的模型,并检查它在真实样本上的表现。对应的我们在实际数据上训练我们的模型来做一些分类任务,并且检查它对生成的数据的执行情况。如果它在两种情况下都能正常工作,你可以随意将生成模型中的样本添加到你的实际数据中并再次重新训练,你应该期望获得性能。
NVIDIA展示了这种方法的惊人实例:他们使用GAN来增加具有不同疾病的医学脑CT图像的数据集,并且表明仅使用经典数据的分类性能是78.6%的灵敏度和88.4%的特异性。通过添加合成数据增强,可以增加到85.7%的灵敏度和92.4%的特异性。
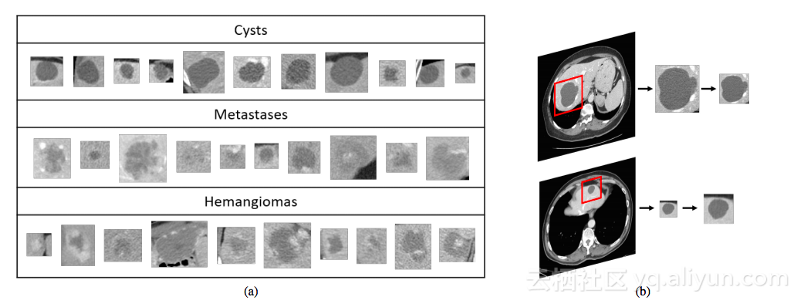
https://arxiv.org/pdf/1803.01229.pdf
2.隐私保护
许多公司的数据可能是秘密的,敏感的(包含患者诊断的医疗数据),但有时我们需要与顾问或研究人员等第三方分享。如果我们只想分享关于我们的数据的一般信息,包括最重要的模式,对象的细节和形状,我们可以使用生成模型来抽样我们的数据示例以与其他人分享。这样我们就不会分享任何确切的机密数据,只是看起来完全像它的东西。
更困难的情况是我们想要秘密共享数据。当然,我们有不同的加密方案,如同态加密,但它们有已知的缺点,例如在10GB代码中隐藏1MB信息。2016年,谷歌开辟了一条关于使用GAN竞争框架加密问题的新研究路径,其中两个网络必须竞争创建代码并破解它:
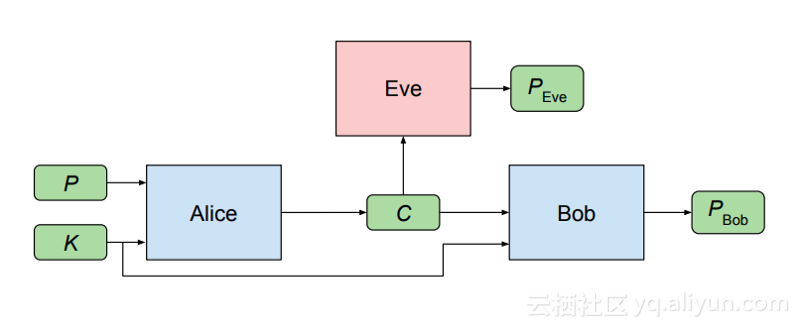
但最好的结果不是获得的代码效率,我们应该记住,通过神经网络获得的表示通常包含有关输入数据的最有用的信息,并且从这个压缩数据我们仍然可以进行分类/回归/聚类。如果我们将“压缩”替换为“加密”,那么这个想法很明确:这是与第三方共享数据而不显示任何数据集的惊人方式。它比匿名甚至假样本生成强得多,可能是下一件大事(当然使用区块链)
3.异常检测
变分自动编码器(VAE)或GAN等主要生成模型由两部分组成。VAE具有编码器和解码器,其中第一个对分布进行建模,第二个重建。GAN由生成器和鉴别器组成,第一个模拟分布,第二个判断它是否接近训练数据。我们可以看到,它们在某种程度上非常相似:有建模和判断部分(在VAE中我们可以考虑将重建视为某种判断),建模部分应该学习数据分布。如果我们将一些不是来自训练样本分发,那么判断部分将会发生什么?训练有素的GAN鉴别器会告诉我们0,并且VAE的重建误差将高于训练数据的平均值。这就是我们接下来要说的:无监督异常探测器,它易于训练和评估。在本文中你可以找到例子是用于异常检测,这里可以找到自动编码的。我还添加了自己的基于自动编码器的粗略草图——用于在Keras中编写的时间序列。
4.判别性建模
深度学习所做的一切都是将输入数据映射到某个空间,在这个空间中,通过SVM或逻辑回归等简单的数学模型可以更容易地分离或解释。生成模型也有自己的映射,我们从VAE开始。Autoencoders将输入样本映射到一些有意义的潜在空间,基本上我们可以直接训练一些模型。它有意义吗?它是否与仅使用编码器层和训练模型直接进行分类有所不同?确实是。自动编码器的潜在空间是复杂的非线性降维,并且在变分自动编码器的情况下也是多变量分布,这可以比一些随机初始化更好地开始训练判别模型。
GAN对于其他任务来说有点难度。它们被设计为从随机种子生成样本,并且不期望任何输入。但我们仍然可以至少以两种方式利用它们作为分类器,第一个已经研究过的,就是利用鉴别器将生成的样本分类到不同的类别,同时只是告诉它是真的还是假的。我们可以期望从获得的分类器更好地规则化(因为它已经看到不同类型的噪声和输入数据的扰动)并且具有用于异常值/异常的额外类:
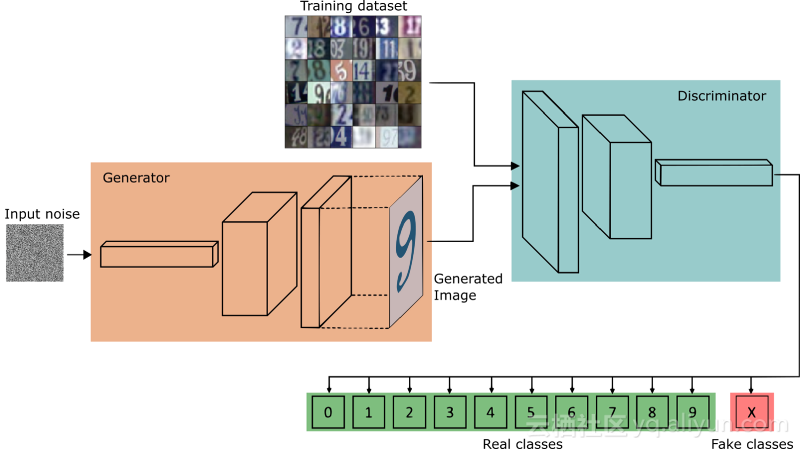
5.域迁移(Domain adaptation)
我认为,这是最强大的用处之一。在实践中,我们几乎从未拥有相同的数据源来训练模型并在现实世界环境中运行它们。在计算机视觉中,不同的光线条件、相机设置或天气可以使非常准确的模型变得无用。在NLP/语音分析中,俚语或重音会破坏你在“语法正确”上训练的模型的表现。在信号处理中,你很可能拥有完全不同的设备来捕获数据以训练模型和生产。我们知道机器学习模型执行是从一个条件到另一个条件的映射,保留主要内容,但要更改细节。

例如,如果你正在处理应该在某种CCTV摄像机上工作的应用程序,但是你已经在高分辨率图像上训练了你的模型,那么你可以尝试使用GAN来对图像进行去噪处理并对其进行增强。我可以从信号处理领域提供更激进的例子:有很多与手机加速度计数据相关的数据集,描述了不同的人的活动。但是,如果你想在腕带上应用受过手机数据训练的模型,该怎么办?GAN可以尝试帮助你还原不同类型的动作。一般来说,生成模型不是从噪声中进行生成,而是一些预定义的先验模型可以帮助你进行域迁移,协方差转换以及与数据差异相关的其他问题。
6.数据处理
我们在前一段谈到了风格转移。我不喜欢的是它的映射函数适用于整个输入,如果我只想换一些照片的鼻子怎么办?或改变汽车的颜色?或者在不完全改变的情况下替换演讲中的某些单词?如果我们想要这样做,那么我们的对象就需用一些有限的因子来描述,例如,脸是眼睛,鼻子,头发,嘴唇等的组合,这些因素有它们自己的属性如颜色、大小等。如果我们可以将带有照片的像素映射到某些...我们可以调整这些因素并使鼻子更大或更小?有一些数学概念允许它:多样性假设,对我们来说好消息是,自动编码器可能实现。

7.对抗训练(Adversarial training)
你可能不同意我添加关于机器学习模型攻击的文字,但它对生成模型(对抗性攻击算法确实非常简单)和对抗性算法影响很大。也许你熟悉对抗性例子的概念:模型输入中的小扰动(甚至可能是图像中的一个像素)导致完全错误的性能。其中一个最基本的方法叫做对抗性训练:基本上是利用对抗性的例子来构建更准确的模型。

如果不深入细节,这意味着我们需要双人游戏:对抗模型需要最大化其影响力,并且存在需要最小化其损失的分类模型。看起来很像GAN,但出于不同的目的:使模型对对抗性攻击更稳定,并通过某种智能数据增强和正规化提高其性能。
小贴士
在本文中,我们已经介绍了几个例子,说明GAN和其他一些生成模型如何用于生成漂亮的图像,旋律或短文本。当然,他们的主要长期目标是生成以正确情况为条件的真实世界对象,但今天我们可以利用他们的分布建模和学习有用的表示来改进我们当前的AI、保护我们的数据、发现异常或适应更多现实世界的案例。我希望你会发现它们很有用,并将适用于你的项目。
本文由阿里云云栖社区组织翻译。
文章原标题《gans-beyond-generation-7-alternative-use-cases》
作者:Alexandr Honchar 译者:虎说八道,审校:。
