引言
美团搜索是美团 App 上最大的连接人和服务的入口,覆盖了团购、外卖、电影、酒店、买菜等各种生活服务。随着用户量快速增长,越来越多的用户在不同场景下都会通过搜索来获取自己想要的服务。理解用户 Query,将用户最想要的结果排在靠前的位置,是搜索引擎最核心的两大步骤。但是,用户输入的 Query 多种多样,既有商户名称和服务品类的 Query,也有商户别名和地址等长尾的 Query,准确刻画 Query 与 Doc 之间的深度语义相关性至关重要。基于 Term 匹配的传统相关性特征可以较好地判断 Query 和候选 Doc 的字面相关性,但在字面相差较大时,则难以刻画出两者的相关性,比如 Query 和 Doc 分别为“英语辅导”和“新东方”时两者的语义是相关的,使用传统方法得到的 Query-Doc 相关性却不一致。
2018 年底,以 Google BERT[1] 为代表的预训练语言模型刷新了多项 NLP 任务的最好水平,开创了 NLP 研究的新范式:即先基于大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成下游的 NLP 任务(文本分类、序列标注、句间关系判断和机器阅读理解等)。美团 AI 平台搜索与 NLP 部算法团队基于美团海量业务语料训练了 MT-BERT 模型,已经将 MT-BERT 应用到搜索意图识别、细粒度情感分析、点评推荐理由、场景化分类等业务场景中 [2]。
作为 BERT 的核心组成结构,Transformer 具有强大的文本特征提取能力,早在多项 NLP 任务中得到了验证,美团搜索也基于 Transformer 升级了核心排序模型,取得了不错的研究成果 [3]。
BERT 简介
近年来,以 BERT 为代表的预训练语言模型在多项 NLP 任务上都获得了不错的效果。下图 1 简要回顾了预训练语言模型的发展历程。2013 年,Google 提出的 Word2vec[4] 通过神经网络预训练方式来生成词向量(Word Embedding),极大地推动了深度自然语言处理的发展。针对 Word2vec 生成的固定词向量无法解决多义词的问题,2018 年,Allen AI 团队提出基于双向 LSTM 网络的 ELMo[5]。ELMo 根据上下文语义来生成动态词向量,很好地解决了多义词的问题。2017 年底,Google 提出了基于自注意力机制的 Transformer[6] 模型。
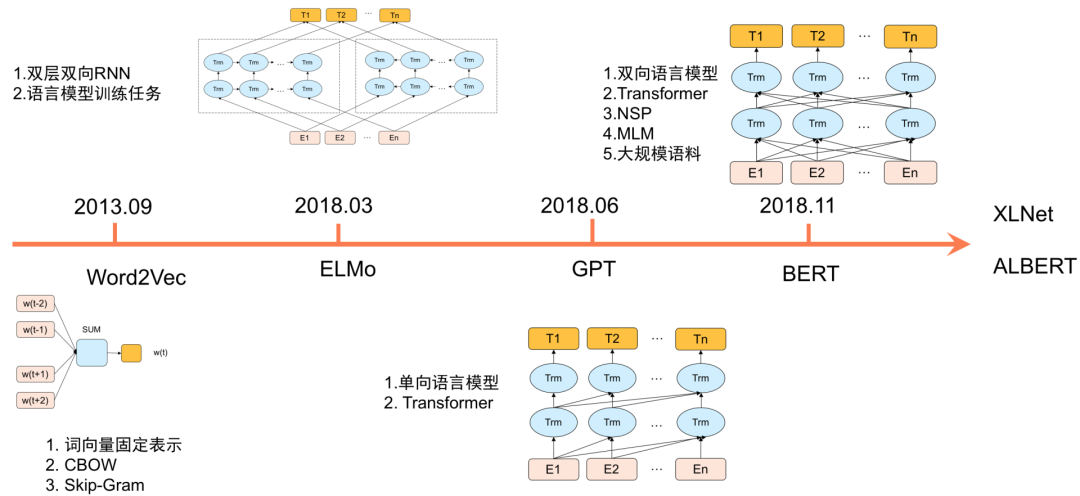
相比 RNN 模型,Transformer 语义特征提取能力更强,具备长距离特征捕获能力,且可以并行训练,在机器翻译等 NLP 任务上效果显著。Open AI 团队的 GPT[7] 使用 Transformer 替换 RNN 进行深层单向语言模型预训练,并通过在下游任务上 Fine-tuning 验证了 Pretrain-Finetune 范式的有效性。在此基础上,Google BERT 引入了 MLM(Masked Language Model)及 NSP(Next Sentence Prediction,NSP)两个预训练任务,并在更大规模语料上进行预训练,在 11 项自然语言理解任务上刷新了最好指标。BERT 的成功启发了大量后续工作,总结如下:
融合更多外部知识的百度 ERNIE[8], 清华 ERNIE[9] 和 K-BERT[10] 等;
优化预训练目标的 ERNIE 2.0[11],RoBERTa[12],SpanBERT[13],StructBERT[14] 等;
优化模型结构或者训练方式的 ALBERT[15] 和 ELECTRA[16]。关于预训练模型的各种后续工作,可以参考复旦大学邱锡鹏老师最近的综述 [17],本文不再赘述。
基于预训练好的 BERT 模型可以支持多种下游 NLP 任务。BERT 在下游任务中的应用主要有两种方式:即 Feature-based 和 Finetune-based。其中 Feature -based 方法将 BERT 作为文本编码器获取文本表示向量,从而完成文本相似度计算、向量召回等任务。而 Finetune-based 方法是在预训练模型的基础上,使用具体任务的部分训练数据进行训练,从而针对性地修正预训练阶段获得的网络参数。该方法更为主流,在大多数任务上效果也更好。
由于 BERT 在 NLP 任务上的显著优势,一些研究工作开始将 BERT 应用于文档排序等信息检索任务中。清华大学 Qiao 等人 [18] 详细对比了 Feature-based 和 Finetune-based 两种应用方式在段落排序(Passage Ranking)中的效果。滑铁卢大学 Jimmy Lin 团队 [19] 针对文档排序任务提出了基于 Pointwise 和 Pairwise 训练目标的 MonoBERT 和 DuoBERT 模型。此外,该团队 [20] 提出融合基于 BERT 的 Query-Doc 相关性和 Query-Sentence 相关性来优化文档排序任务的方案。为了优化检索性能和效果,Bing 广告团队 [21] 提出一种双塔结构的 TwinBERT 分别编码 Query 和 Doc 文本。2019 年 10 月,Google 在其官方博客介绍了 BERT 在 Google 搜索排序和精选摘要(Featured Snippet)场景的应用,BERT 强大的语义理解能力改善了约 10% 的 Google 搜索结果 [22],除了英文网页,Google 也正在基于 BERT 优化其他语言的搜索结果。值得一提的是美团 AI 平台搜索与 NLP 部在 WSDM Cup 2020 检索排序评测任务中提出了基于 Pairwise 模式的 BERT 排序模型和基于 LightGBM 的排序模型,取得了榜单第一名的成绩 [23]。
搜索相关性
美团搜索场景下相关性任务定义如下:给定用户 Query 和候选 Doc(通常为商户或商品),判断两者之间相关性。搜索 Query 和 Doc 的相关性直接反映结果页排序的优劣,将相关性高的 Doc 排在前面,能提高用户搜索决策效率和搜索体验。为了提升结果的相关性,我们在召回、排序等多个方面做了优化,本文主要讨论在排序方面的优化。通过先对 Query 和 Doc 的相关性进行建模,把更加准确的相关性信息输送给排序模型,从而提升排序模型的排序能力。Query 和 Doc 的相关性计算是搜索业务核心技术之一,根据计算方法相关性主要分为字面相关性和语义相关性。
字面相关性
早期的相关性匹配主要是根据 Term 的字面匹配度来计算相关性,如字面命中、覆盖程度、TFIDF、BM25 等。字面匹配的相关性特征在美团搜索排序模型中起着重要作用,但字面匹配有它的局限,主要表现在:
词义局限 :字面匹配无法处理同义词和多义词问题,如在美团业务场景下“宾馆”和“旅店”虽然字面上不匹配,但都是搜索“住宿服务”的同义词;而“COCO”是多义词,在不同业务场景下表示的语义不同,可能是奶茶店,也可能是理发店。
结构局限 :“蛋糕奶油”和“奶油蛋糕”虽词汇完全重合,但表达的语义完全不同。 当用户搜“蛋糕奶油”时,其意图往往是找“奶油”,而搜“奶油蛋糕”的需求基本上都是“蛋糕”。
语义相关性
为了解决上述问题,业界工作包括传统语义匹配模型和深度语义匹配模型。传统语义匹配模型包括:
隐式模型 :将 Query、Doc 都映射到同一个隐式向量空间,通过向量相似度来计算 Query-Doc 相关性,例如使用主题模型 LDA[24] 将 Query 和 Doc 映射到同一向量空间;
翻译模型 :通过统计机器翻译方法将 Doc 进行改写后与 Query 进行匹配 [25]。
这些方法弥补了字面匹配方法的不足,不过从实际效果上来看,还是无法很好地解决语义匹配问题。随着深度自然语言处理技术的兴起,基于深度学习的语义匹配方法成为研究热点,主要包括基于表示的匹配方法(Representation-based)和基于交互的匹配方法(Interaction-based)。
基于表示的匹配方法 :使用深度学习模型分别表征 Query 和 Doc,通过计算向量相似度来作为语义匹配分数。微软的 DSSM[26] 及其扩展模型属于基于表示的语义匹配方法,美团搜索借鉴 DSSM 的双塔结构思想,左边塔输入 Query 信息,右边塔输入 POI、品类信息,生成 Query 和 Doc 的高阶文本相关性、高阶品类相关性特征,应用于排序模型中取得了很好的效果。此外,比较有代表性的表示匹配模型还有百度提出 SimNet[27],中科院提出的多视角循环神经网络匹配模型(MV-LSTM)[28] 等。
基于交互的匹配方法 :这种方法不直接学习 Query 和 Doc 的语义表示向量,而是在神经网络底层就让 Query 和 Doc 提前交互,从而获得更好的文本向量表示,最后通过一个 MLP 网络获得语义匹配分数。代表性模型有华为提出的基于卷积神经网络的匹配模型 ARC-II[29],中科院提出的基于矩阵匹配的的层次化匹配模型 MatchPyramid[30]。
基于表示的匹配方法优势在于 Doc 的语义向量可以离线预先计算,在线预测时只需要重新计算 Query 的语义向量,缺点是模型学习时 Query 和 Doc 两者没有任何交互,不能充分利用 Query 和 Doc 的细粒度匹配信号。基于交互的匹配方法优势在于 Query 和 Doc 在模型训练时能够进行充分的交互匹配,语义匹配效果好,缺点是部署上线成本较高。
BERT 语义相关性
BERT 预训练使用了大量语料,通用语义表征能力更好,BERT 的 Transformer 结构特征提取能力更强。中文 BERT 基于字粒度预训练,可以减少未登录词(OOV)的影响,美团业务场景下存在大量长尾 Query(如大量数字和英文复合 Query)字粒度模型效果优于词粒度模型。此外,BERT 中使用位置向量建模文本位置信息,可以解决语义匹配的结构局限。综上所述,我们认为 BERT 应用在语义匹配任务上会有更好的效果,基于 BERT 的语义匹配有两种应用方式:
Feature-based :属于基于表示的语义匹配方法。类似于 DSSM 双塔结构,通过 BERT 将 Query 和 Doc 编码为向量,Doc 向量离线计算完成进入索引,Query 向量线上实时计算,通过近似最近邻(ANN)等方法实现相关 Doc 召回。
Finetune-based :属于基于交互的语义匹配方法,将 Query 和 Doc 对输入 BERT 进行句间关系 Fine-tuning,最后通过 MLP 网络得到相关性分数。
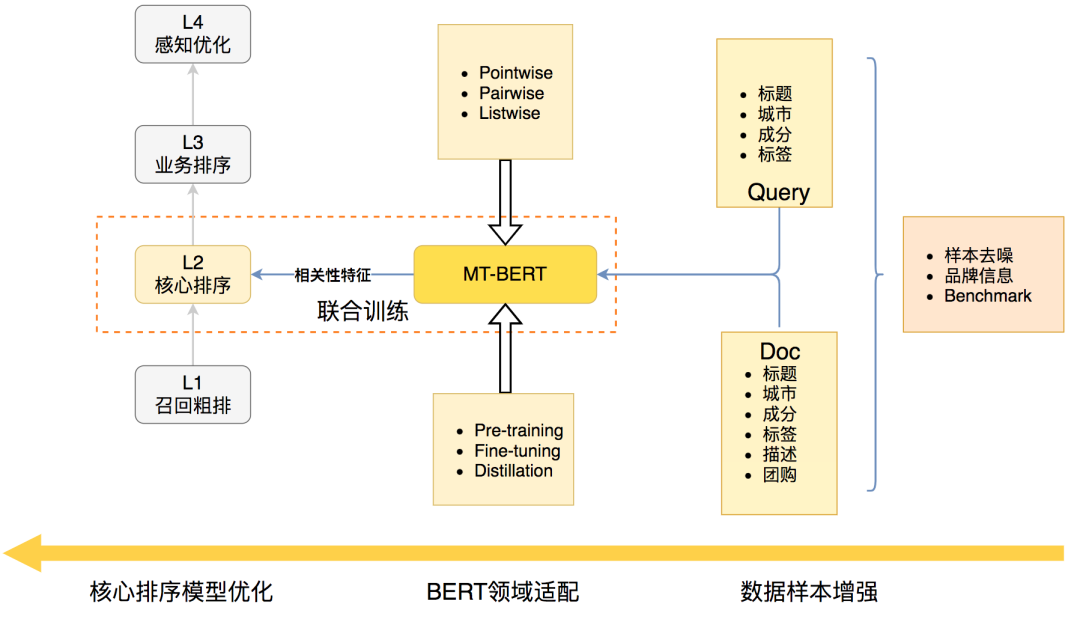
Feature-based 方式是经过 BERT 得到 Query 和 Doc 的表示向量,然后计算余弦相似度,所有业务场景下 Query-Doc 相似度都是固定的,不利于适配不同业务场景。此外,在实际场景下为海量 Doc 向量建立索引存储成本过高。因此,我们选择了 Finetune-based 方案,利用搜索场景中用户点击数据构造训练数据,然后通过 Fine-tuning 方式优化 Query-Doc 语义匹配任务。图 2 展示了基于 BERT 优化美团搜索核心排序相关性的技术架构图,主要包括三部分:
数据样本增强 :由于相关性模型的训练基于搜索用户行为标注的弱监督数据,我们结合业务经验对数据做了去噪和数据映射。为了更好地评价相关性模型的离线效果,我们构建了一套人工标注的 Benchmark 数据集,指导模型迭代方向。
BERT 领域适配 :美团业务场景中,Query 和 Doc 以商户、商品、团购等短文本为主,除标题文本以外,还存在商户 / 商品描述、品类、地址、图谱标签等结构化信息。我们首先改进了 MT-BERT 预训练方法,将品类、标签等文本信息也加入 MT-BERT 预训练过程中。在相关性 Fine-tuning 阶段,我们对训练目标进行了优化,使得相关性任务和排序任务目标更加匹配,并进一步将两个任务结合进行联合训练。此外,由于 BERT 模型前向推理比较耗时,难以满足上线要求,我们通过知识蒸馏将 12 层 BERT 模型压缩为符合上线要求的 2 层小模型,且无显著的效果损失。
排序模型优化 :核心排序模型(本文记为 L2 模型)包括 LambdaDNN[31]、TransformerDNN[3]、MultiTaskDNN 等深度学习模型。给定,我们将基于 BERT 预测的 Query-Doc 相关性分数作为特征用于 L2 模型的训练中。
算法探索
数据增强
BERT Fine-tuning 任务需要一定量标注数据进行迁移学习训练,美团搜索场景下 Query 和 Doc 覆盖多个业务领域,如果采用人工标注的方法为每个业务领域标注一批训练样本,时间和人力成本过高。我们的解决办法是使用美团搜索积累的大量用户行为数据(如浏览、点击、下单等), 这些行为数据可以作为弱监督训练数据。在 DSSM 模型进行样本构造时,每个 Query 下抽取 1 个正样本和 4 个负样本,这是比较常用的方法,但是其假设 Query 下的 Doc 被点击就算是相关的,这个假设在实际的业务场景下会给模型引入一些噪声。
此处以商家(POI)搜索为例,理想情况下如果一个 POI 出现在搜索结果里,但是没有任何用户点击,可认为该 POI 和 Query 不相关;如果该 POI 有点击或下单行为,可认为该 POI 和 Query 相关。下单行为数据是用户“用脚投票”得来的,具有更高的置信度,因此我们使用下单数据作为正样本,使用未点击过的数据构造负样本,然后结合业务场景对样本进一步优化。数据优化主要包括对样本去噪和引入品牌数据两个方面。此外,为了评测算法离线效果,我们从构造样本中随机采样 9K 条样本进行了人工标注作为 Benchmark 数据集。
样本去噪
无意义单字 Query 过滤。由于单字 Query 表达的语义通常不完整,用户点击行为也比较随机,如 < 优,花漾星球专柜(中央大道倍客优)>,这部分数据如果用于训练会影响最终效果。我们去除了包含无意义单字 Query 的全部样本。
正样本从用户下单的 POI 中进行随机采样,且过滤掉 Query 只出现在 POI 的分店名中的样本,如 < 大润发,小龙坎老火锅(大润发店)>,虽然 Query 和 POI 字面匹配,但其实是不相关的结果。
负样本尝试了两种构造方法:全局随机负采样和 Skip-Above 采样。
全局随机负采样 :用户没有点击的 POI 进行随机采样得到负例。我们观察发现随机采样同样存在大量噪声数据,补充了两项过滤规则来过滤数据。① 大量的 POI 未被用户点击是因为不是离用户最近的分店,但 POI 和 Query 是相关的,这种类型的样例需要过滤掉,如 < 蛙小侠 ,蛙小侠(新北万达店)>。② 用户 Query 里包含品牌词,并且 POI 完全等同于品牌词的,需要从负样本中过滤,如 < 德克士吃饭 ,德克士 >。
Skip-Above 采样 :受限于 App 搜索场景的展示屏效,无法保证召回的 POI 一次性得到曝光。若直接将未被点击的 POI 作为负例,可能会将未曝光但相关的 POI 错误地采样为负例。为了保证训练数据的准确性,我们采用 Skip-Above 方法,剔除这些噪音负例,即从用户点击过的 POI 之上没有被点击过的 POI 中采样负例(假设用户是从上往下浏览的 POI)。
品牌样本优化
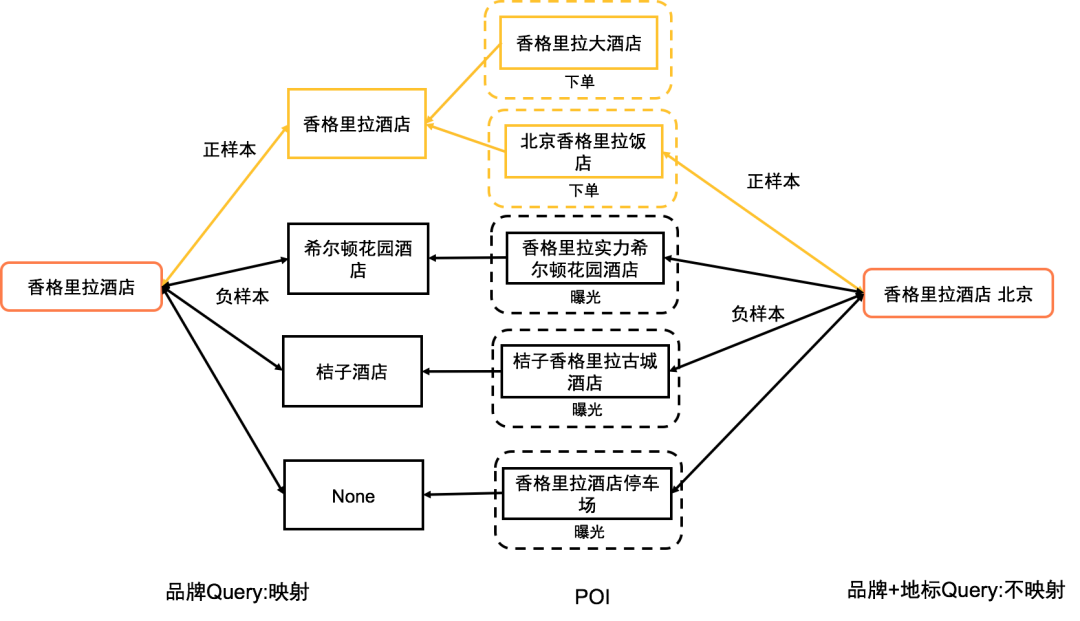
美团商家中有很多品牌商家,通常品牌商家拥有数百上千的 POI,如“海底捞”、“肯德基”、“香格里拉酒店”等,品牌 POI 名称多是“品牌 + 地标”文本形式,如“北京香格里拉饭店”。对 Query 和 POI 的相关性进行建模时,如果仅取 Query 和 POI 名进行相关性训练,POI 名中的“地标”会给模型带来很大干扰。例如,用户搜“香格里拉酒店”时会召回品牌“香格里拉酒店”的分店,如“香格里拉酒店”和“北京香格里拉饭店”等,相关性模型受地标词影响,会给不同分店会打出不同的相关性分数,进而影响到后续排序模型的训练。因此,我们对于样本中的品牌搜索样本做了针对性优化。搜索品牌词有时会召回多个品牌的结果,假设用户搜索的品牌排序靠后,而其他品牌排序靠前会严重影响到用户体验,因此对 Query 和 POI 相关性建模时召回结果中其他品牌的 POI 可认为是不相关样本。针对上述问题,我们利用 POI 的品牌信息对样本进行了重点优化。
POI 名映射到品牌 :在品牌搜 Query 不包含地标词的时候,将 POI 名映射到品牌(非品牌 POI 不进行映射),从而消除品牌 POI 分店名中地标词引入的噪声。如 Query 是“香格里拉酒店”,召回的“香格里拉大酒店”和“北京香格里拉饭店”统一映射为品牌名“香格里拉酒店”。Query 是“品牌 + 地标”形式(如“香格里拉饭店 北京”)时,用户意图明确就是找某个地点的 POI,不需要进行映射,示例如下图 3 所示。
负样本过滤 :如果搜索词是品牌词,在选取负样本的时候只在其他品牌的样本中选取。如 POI 为“香格里拉实力希尔顿花园酒店”、“桔子香格里拉古城酒店”时,同 Query “香格里拉酒店”虽然字面很相似,但其明显不是用户想要的品牌。
经过样本去噪和品牌样本优化后,BERT 相关性模型在 Benchmark 上的 Accuracy 提升 23BP,相应地 L2 排序排序模型离线 AUC 提升 17.2BP。
模型优化
知识融合
我们团队基于美团业务数据构建了餐饮娱乐领域知识图谱—“美团大脑”[32],对于候选 Doc(POI/SPU),通过图谱可以获取到该 Doc 的大量结构化信息,如地址、品类、团单,场景标签等。美团搜索场景中的 Query 和 Doc 都以短文本为主,我们尝试在预训练和 Fine-tuning 阶段融入图谱品类和实体信息,弥补 Query 和 Doc 文本信息的不足,强化语义匹配效果。
引入品类信息的预训练
由于美团搜索多模态的特点,在某些情况下,仅根据 Query 和 Doc 标题文本信息很难准确判断两者之间的语义相关性。如 < 考研班,虹蝶教育 >,Query 和 Doc 标题文本相关性不高,但是“虹蝶教育”三级品类信息分别是“教育 - 升学辅导 - 考研”,引入相关图谱信息有助于提高模型效果,我们首先基于品类信息做了尝试。
在相关性判别任务中,BERT 模型的输入是对。对于每一个输入的 Token,它的表征由其对应的词向量(Token Embedding)、片段向量(Segment Embedding)和位置向量(Position Embedding)相加产生。为了引入 Doc 品类信息,我们将 Doc 三级品类信息拼接到 Doc 标题之后,然后跟 Query 进行相关性判断,如图 4 所示。
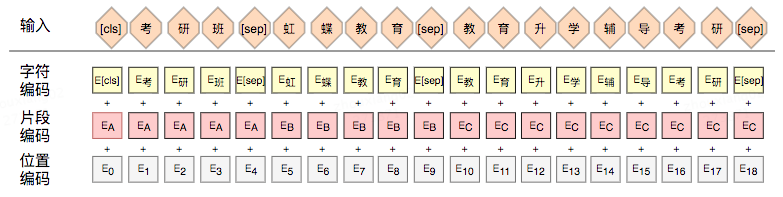
对于模型输入部分,我们将 Query、Doc 标题、三级类目信息拼接,并用 [SEP] 分割,区分 3 种不同来源信息。对于段向量,原始的 BERT 只有两种片段编码 EA 和 EB,在引入类目信息的文本信息后,引入额外的片段编码 EC。引入额外片段编码的作用是防止额外信息对 Query 和 Doc 标题产生交叉干扰。由于我们改变了 BERT 的输入和输出结构,无法直接基于 MT-BERT 进行相关性 Fine-tuning 任务。我们对 MT-BERT 的预训练方式做了相应改进,BERT 预训练的目标之一是 NSP(Next Sentence Prediction),在搜索场景中没有上下句的概念,在给定用户的搜索关键词和商户文本信息后,判断用户是否点击来取代 NSP 任务。
添加品类信息后,BERT 相关性模型在 Benchmark 上的 Accuracy 提升 56BP,相应地 L2 排序模型离线 AUC 提升 6.5BP。
引入实体成分识别的多任务 Fine-tuning
在美团搜索场景中,Query 和 Doc 通常由不同实体成分组成,如美食、酒店、商圈、品牌、地标和团购等。除了文本语义信息,这些实体成分信息对于 Query-Doc 相关性判断至关重要。如果 Query 和 Doc 语义相关,那两者除了文本语义相似外,对应的实体成分也应该相似。例如,Query 为“Helens 海伦司小酒馆”,Doc 为“Helens 小酒馆(东鼎购物中心店)”,虽然文本语义不完全匹配,但二者的主要的实体成分相似(主体成分为品牌 +POI 形式),正确的识别出 Query/Doc 中的实体成分有助于相关性的判断。微软的 MT-DNN[33] 已经证明基于预训练模型的多任务 Fine-tuning 可以提升各项子任务效果。由于 BERT Fine-tuning 任务也支持命名实体识别(NER)任务,因而我们在 Query-Doc 相关性判断任务的基础上引入 Query 和 Doc 中实体成分识别的辅助任务,通过对两个任务的联合训练来优化最终相关性判别结果,模型结构如下图 5 所示:
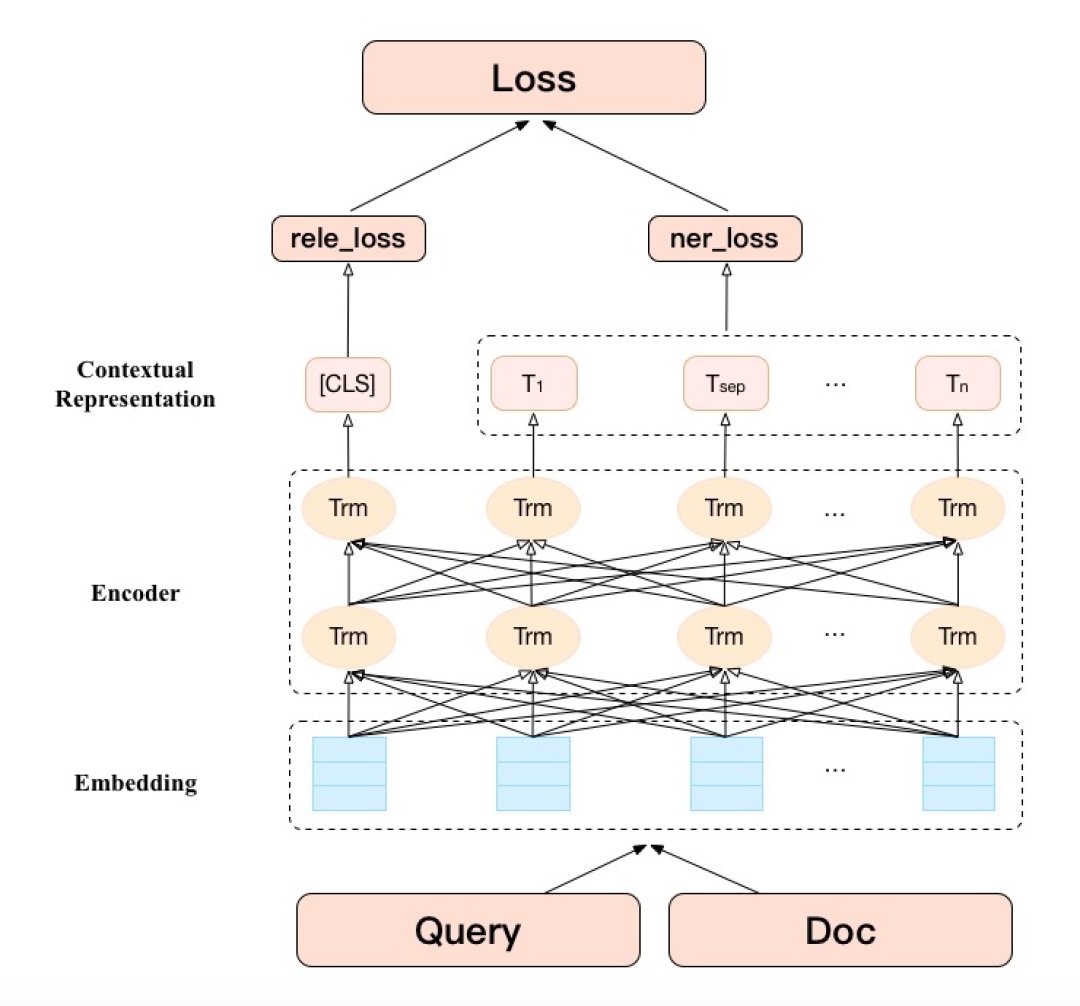
多任务学习模型的损失函数由两部分组成,分别是相关性判断损失函数和命名实体识别损失函数。其中相关性损失函数由 [CLS] 位的 Embedding 计算得到,而实体成分识别损失函数由每个 Token 的 Embedding 计算得到。2 种损失函数相加即为最终优化的损失函数。在训练命名实体识别任务时,每个 Token 的 Embedding 获得了和自身实体相关的信息,从而提升了相关性任务的效果。
引入实体成分识别的多任务 Fine-tuning 方式后,BERT 相关性模型在 Benchmark 上的 Accuracy 提升 219BP,相应地 L2 排序模型 AUC 提升 17.8BP。
Pairwise Fine-tuning
Query-Doc 相关性最终作为特征加入排序模型训练中,因此我们也对 Fine-tuning 任务的训练目标做了针对性改进。基于 BERT 的句间关系判断属于二分类任务,本质上是 Pointwise 训练方式。Pointwise Fine-tuning 方法可以学习到很好的全局相关性,但忽略了不同样本之前的偏序关系。如对于同一个 Query 的两个相关结果 DocA 和 DocB,Pointwise 模型只能判断出两者都与 Query 相关,无法区分 DocA 和 DocB 相关性程度。为了使得相关性特征对于排序结果更有区分度,我们借鉴排序学习中 Pairwise 训练方式来优化 BERT Fine-tuning 任务。
Pairwise Fine-tuning 任务输入的单条样本为三元组,对于同一 Query 的多个候选 Doc,选择任意一个正例和一个负例组合成三元组作为输入样本。在下游任务中只需要使用少量的 Query 和 Doc 相关性的标注数据(有监督训练样本),对 BERT 模型进行相关性 Fine-tuning,产出 Query 和 Doc 的相关性特征。Pairwise Fine-tuning 的模型结构如下图 6 所示:
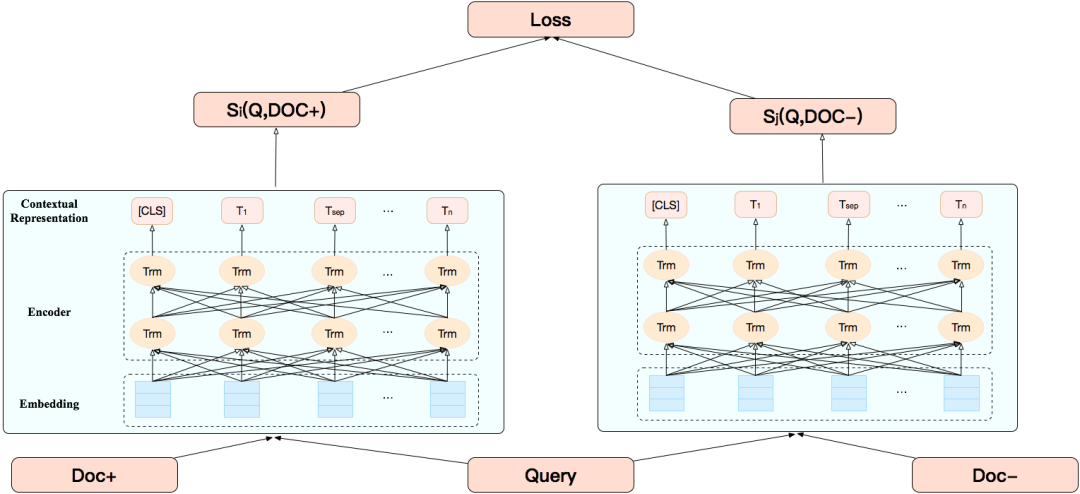
对于同一 Query 的候选 Doc,选择两个不同标注的 Doc,其中相关文档记为 Doc+, 不相关文档记 Doc-。输入层通过 Lookup Table 将 Query, Doc+ 以及 Doc- 的单词转换为 Token 向量,同时会拼接位置向量和片段向量,形成最终输入向量。接着通过 BERT 模型可以分别得到(Query, Doc+)以及(Query, Doc-)的语义相关性表征,即 BERT 的 CLS 位输出。经过 Softmax 归一化后,可以分别得到(Query, Doc+)和(Query, Doc-)的语义相似度打分。
对于同一 Query 的候选 Doc,选择两个不同标注的 Doc,其中相关文档记为 Doc+, 不相关文档记 Doc-。输入层通过 Lookup Table 将 Query, Doc+ 以及 Doc- 的单词转换为 Token 向量,同时会拼接位置向量和片段向量,形成最终输入向量。接着通过 BERT 模型可以分别得到(Query, Doc+)以及(Query, Doc-)的语义相关性表征,即 BERT 的 CLS 位输出。经过 Softmax 归一化后,可以分别得到(Query, Doc+)和(Query, Doc-)的语义相似度打分。
Pairwise Fine-tuning 除了输入样本上的变化,为了考虑搜索场景下不同样本之间的偏序关系,我们参考 RankNet[34] 的方式对训练损失函数做了优化。令为同一个 Query 下相比更相关的概率,其中和分别为和的模型打分,则:
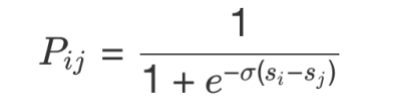
使用交叉熵损失函数,令表示样本对的真实标记,当比更相关时(即为正例而为负例),为 1,否则为 -1,损失函数可以表示为:
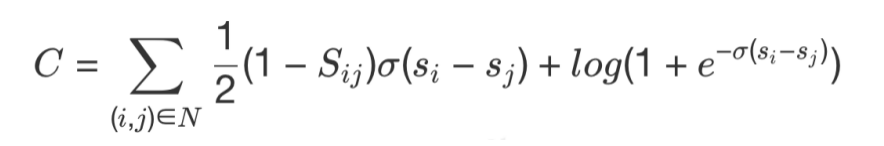
其中 N 表示所有在同 Query 下的 Doc 对。
使用 Pairwise Fine-tuning 方式后,BERT 相关性模型在 Benchmark 上的 Accuracy 提升 925BP,相应地 L2 排序模型的 AUC 提升 19.5BP。
联合训练
前文所述各种优化属于两阶段训练方式,即先训练 BERT 相关性模型,然后训练 L2 排序模型。为了将两者深入融合,在排序模型训练中引入更多相关性信息,我们尝试将 BERT 相关性 Fine-tuning 任务和排序任务进行端到端的联合训练。
由于美团搜索涉及多业务场景且不同场景差异较大,对于多场景的搜索排序,每个子场景进行单独优化效果好,但是多个子模型维护成本更高。此外,某些小场景由于训练数据稀疏无法学习到全局的 Query 和 Doc 表征。我们设计了基于 Partition-model 的 BERT 相关性任务和排序任务的联合训练模型,Partition-model 的思想是利用所有数据进行全场景联合训练,同时一定程度上保留每个场景特性,从而解决多业务场景的排序问题,模型结构如下图 7 所示:
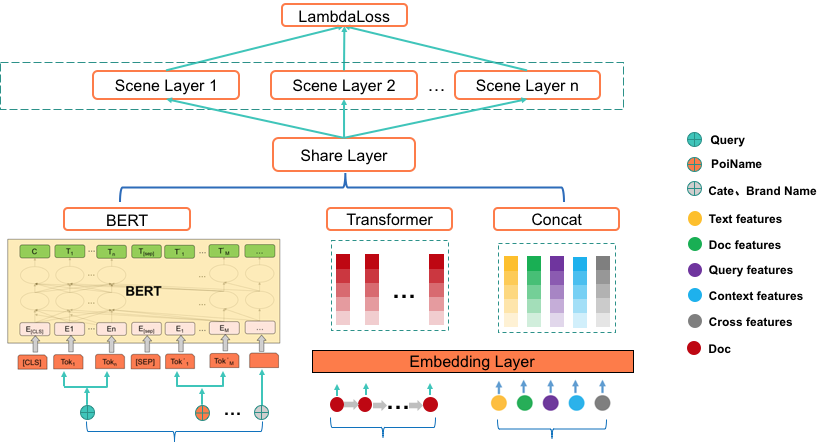
输入层 :模型输入是由文本特征向量、用户行为序列特征向量和其他特征向量 3 部分组成。
文本特征向量使用 BERT 进行抽取,文本特征主要包括 Query 和 POI 相关的一些文本(POI 名称、品类名称、品牌名称等)。将文本特征送入预训练好的 MT-BERT 模型,取 CLS 向量作为文本特征的语义表示。
用户行为序列特征向量使用 Transformer 进行抽取 [3]。
其他特征主要包括:① 统计类特征,包含 Query、Doc 等维度的特征以及它们之间的交叉特征,使用这些特征主要是为了丰富 Query 和 Doc 的表示,更好地辅助相关性任务训练。② 文本特征,这部分的特征同 1 中的文本特征,但是使用方式不同,直接将文本分词后做 Embedding,端到端的学习文本语义表征。③ 传统的文本相关性特征,包括 Query 和 Doc 的字面命中、覆盖程度、BM25 等特征,虽然语义相关性具有较好的作用,但字面相关性仍然是一个不可或缺的模块,它起到信息补充的作用。
共享层 :底层网络参数是所有场景网络共享。
场景层 :根据业务场景进行划分,每个业务场景单独设计网络结构,打分时只经过所在场景的那一路。
损失函数 :搜索业务更关心排在页面头部结果的好坏,将更相关的结果排到头部,用户会获得更好的体验,因此选用优化 NDCG 的 Lambda Loss[34]。
联合训练模型目前还在实验当中,离线实验已经取得了不错的效果,在验证集上 AUC 提升了 234BP。目前,场景切分依赖 Query 意图模块进行硬切分,后续自动场景切分也值得进行探索。
应用实践
由于 BERT 的深层网络结构和庞大参数量,如果要部署上线,实时性上面临很大挑战。在美团搜索场景下,我们对基于 MT-BERT Fine-tuning 好的相关性模型(12 层)进行了 50QPS 压测实验,在线服务的 TP99 增加超过 100ms,不符合工程上线要求。我们从两方面进行了优化,通过知识蒸馏压缩 BERT 模型,优化排序服务架构支持蒸馏模型上线。
模型轻量化
为了解决 BERT 模型参数量过大、前向计算耗时的问题,常用轻量化方法有三种:
知识蒸馏 :模型蒸馏是在一定精度要求下,将大模型学到的知识迁移到另一个轻量级小模型上,目的是降低预测计算量的同时保证预测效果。Hinton 在 2015 年的论文中阐述了核心思想 [35],大模型一般称作 Teacher Model,蒸馏后的小模型一般称作 Student Model。具体做法是先在训练数据上学习 Teacher Model,然后 Teacher Model 对无标注数据进行预测得到伪标注数据,最后使用伪标注数据训练 Student Model。HuggingFace 提出的 DistilBERT[36] 和华为提出的 TinyBERT[37] 等 BERT 的蒸馏模型都取得了不错的效果,在保证效果的情况下极大地提升了模型的性能。
模型裁剪 :通过模型剪枝减少参数的规模。
低精度量化 :在模型训练和推理中使用低精度(FP16 甚至 INT8、二值网络)表示取代原有精度(FP32)表示。
在 Query 意图分类任务 [2] 中,我们基于 MT-BERT 裁剪为 4 层小模型达到了上线要求。意图分类场景下 Query 长度偏短,语义信息有限,直接裁剪掉几层 Transformer 结构对模型的语义表征能力不会有太大的影响。在美团搜索的场景下,Query 和 Doc 拼接后整个文本序列变长,包含更复杂的语义关系,直接裁剪模型会带来更多的性能损失。因此,我们在上线 Query-Doc 相关性模型之前,采用知识蒸馏方式,在尽可能在保持模型性能的前提下对模型层数和参数做压缩。两种方案的实验效果对比见下表 1:
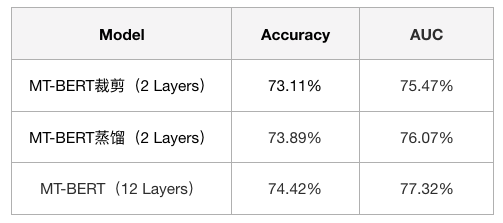
在美团搜索核心排序的业务场景下,我们采用知识蒸馏使得 BERT 模型在对响应时间要求苛刻的搜索场景下符合了上线的要求,并且效果无显著的性能损失。知识蒸馏(Knowledge Distillation)核心思想是通过迁移知识,从而通过训练好的大模型得到更加适合推理的小模型。首先我们基于 MT-BERT(12 Layers),在大规模的美团点评业务语料上进行知识蒸馏得到通用的 MT-BERT 蒸馏模型(6 Layers),蒸馏后的模型可以作为具体下游任务 Fine-tuning 时的初始化模型。在美团搜索的场景下,我们进一步基于通用的 MT-BERT 蒸馏模型(6 Layers)进行相关性任务 Fine-tuning ,得到 MT-BERT 蒸馏(2 Layers)进行上线。
排序服务架构优化
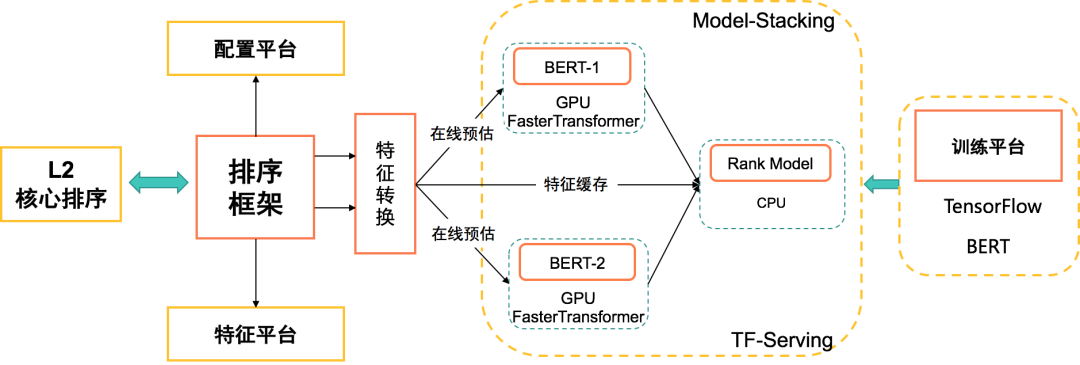
美团搜索线上排序服务框架如上图 8 所示,主要包括以下模块:
模型在线预估框架(Augur) :支持语言化定义特征,配置化加载和卸载模型与特征,支持主流线性模型与 TF 模型的在线预估;基于 Augur 可以方便地构建功能完善的无状态、分布式的模型预估服务。为了能方便将 BERT 特征用于排序模型,Augur 团队开发了 Model Stacking 功能,完美支持了 BERT as Feature;这种方式将模型的分数当做一个特征,只需要在 Augur 服务模型配置平台上进行特征配置即可,很好地提升了模型特征的迭代效率。
搜索模型实验平台(Poker) :支持超大规模数据和模型的离线特征抽取、模型训练,支持 BERT 模型自助训练 /Fine-tuning 和预测;同时打通了 Augur 服务,训练好的模型可以实现一键上线,大大提升了模型的实验效率。
TF-Serving 在线模型服务 :L2 排序模型、BERT 模型上线使用 TF-Serving 进行部署。TF-Serving 预测引擎支持 Faster Transformer[38] 加速 BERT 推理,提升了线上的预估速度。
为了进一步提升性能,我们将头部 Query 进行缓存只对长尾 Query 进行在线打分,线上预估结合缓存的方式,即节约了 GPU 资源又提升了线上预估速度。经过上述优化,我们实现了 50 QPS 下,L2 模型 TP99 只升高了 2ms,满足了上线的要求。
线上效果
针对前文所述的各种优化策略,除了离线 Benchmark 上的效果评测之外,我们也将模型上线进行了线上 AB 评测,Baseline 是当前未做任何优化的排序模型,我们独立统计了各项优化在 Baseline 基础上带来的变化,由于线上真实环境影响因素较多,为了确保结论可信,我们同时统计了 QVCTR 和 NDCG 两个指标,结果如表 2 所示:
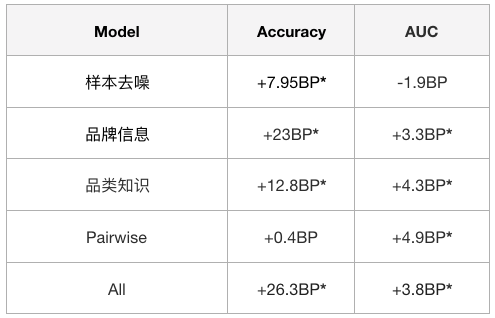
从表 2 可以看出,各项优化对线上排序核心指标都带来稳定的提升。用户行为数据存在大量噪声不能直接拿来建模,我们基于美团搜索排序业务特点设计了一些规则对训练样本进行优化,还借助 POI 的品牌信息对样本进行映射和过滤。通过人工对样本进行评测发现,优化后的样本更加符合排序业务特点以及“人”对相关性的认知,同时线上指标的提升也验证了我们优化的有效性。知识融合的 BERT 模型引入大量结构化文本信息,弥补了 POI 名本身文本信息少的问题,排序模型 CTR 和 NDCG 都有明显的提升。对数据样本的优化有了一定的效果。
为了更加匹配业务场景,我们从模型的角度进行优化,模型损失函数改用排序任务常用的 Pairwise Loss,其考虑了文档之间的关系更加贴合排序任务场景,线上排序模型 NDCG 取得了一定的提升。
总结与展望
本文总结了搜索与 NLP 算法团队基于 BERT 在美团搜索核心排序落地的探索过程和实践经验,包括数据增强、模型优化和工程实践。在样本数据上,我们结合了美团搜索业务领域知识,基于弱监督点击日志构建了高质量的训练样本;针对美团搜索多模态特点,在预训练和 Fine-tuning 阶段融合图谱品类和标签等信息,弥补 Query 和 Doc 文本较短的不足,强化文本匹配效果。
在算法模型上,我们结合搜索排序优化目标,引入了 Pairwise/Listwise 的 Fine-tuning 训练目标,相比 Pointwise 方式在相关性判断上更有区分度。这些优化在离线 Benchmark 评测和线上 AB 评测中带来了不同幅度的指标提升,改善了美团搜索的用户体验。
在工程架构上,针对 BERT 在线预估性能耗时长的问题,参考业界经验,我们采用了 BERT 模型轻量化的方案进行模型蒸馏裁剪,既保证模型效果又提升了性能,同时我们对整体排序架构进行了升级,为后续快速将 BERT 应用到线上预估奠定了良好基础。
搜索与 NLP 算法团队会持续进行探索 BERT 在美团搜索中的应用落地,我们接下来要进行以下几个优化:
融合知识图谱信息对长尾流量相关性进行优化 :美团搜索承接着多达几十种生活服务的搜索需求,当前头部流量相关性问题已经较好地解决,长尾流量的相关性优化需要依赖更多的高质量数据。我们将利用知识图谱信息,将一些结构化先验知识融入到 BERT 预训练中,对长尾 Query 的信息进行增强,使其可以更好地进行语义建模。
相关性与其他任务联合优化 :美团搜索场景下 Query 和候选 Doc 都更结构化,除文本语义匹配外,Query/Doc 文本中蕴含的实体成分、意图、类目也可以用于辅助相关性判断。目前,我们将相关性任务和成分识别任务结合进行联合优化已经取得一定效果。后续我们考虑将意图识别、类目预测等任务加入相关性判断中,多视角、更全面地评估 Query-Doc 的相关性。
BERT 相关性模型和排序模型的深入融合 :当前两个模型属于两阶段训练方式,将 BERT 语义相关性作为特征加入排序模型来提升点击率。语义相关性是影响搜索体验的重要因素之一,我们将 BERT 相关性和排序模型进行端到端联合训练,将相关性和点击率目标进行多目标联合优化,提升美团搜索排序的综合体验。
参考资料
[1] Devlin, Jacob, et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[2] 杨扬、佳昊等. 美团BERT 的探索和实践
[3] 肖垚、家琪等. Transformer 在美团搜索排序中的实践
[4] Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
[5] Peters, Matthew E., et al. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018).
[6] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
[7] Radford, Alec, et al. “ Improving language understanding by generative pre-training .”
[8] Sun, Yu, et al. “Ernie: Enhanced representation through knowledge integration.” arXiv preprint arXiv:1904.09223 (2019).
[9] Zhang, Zhengyan, et al. “ERNIE: Enhanced language representation with informative entities.” arXiv preprint arXiv:1905.07129 (2019).
[10] Liu, Weijie, et al. “K-bert: Enabling language representation with knowledge graph.” arXiv preprint arXiv:1909.07606 (2019).
[11] Sun, Yu, et al. “Ernie 2.0: A continual pre-training framework for language understanding.” arXiv preprint arXiv:1907.12412 (2019).
[12] Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
[13] Joshi, Mandar, et al. “Spanbert: Improving pre-training by representing and predicting spans.” Transactions of the Association for Computational Linguistics 8 (2020): 64-77.
[14] Wang, Wei, et al. “StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding.” arXiv preprint arXiv:1908.04577 (2019).
[15] Lan, Zhenzhong, et al. “Albert: A lite bert for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942 (2019)
[16] Clark, Kevin, et al. “Electra: Pre-training text encoders as discriminators rather than generators.” arXiv preprint arXiv:2003.10555 (2020).
[17] Qiu, Xipeng, et al. “Pre-trained Models for Natural Language Processing: A Survey.” arXiv preprint arXiv:2003.08271 (2020).
[18] Qiao, Yifan, et al. “Understanding the Behaviors of BERT in Ranking.” arXiv preprint arXiv:1904.07531 (2019).
[19] Nogueira, Rodrigo, et al. “Multi-stage document ranking with BERT.” arXiv preprint arXiv:1910.14424 (2019).
[20] Yilmaz, Zeynep Akkalyoncu, et al. “Cross-domain modeling of sentence-level evidence for document retrieval.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
[21] Wenhao Lu, et al. “TwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval.” arXiv preprint arXiv: 2002.06275
[22] Pandu Nayak .
[23] 帅朋、会星等. WSDM Cup 2020 检索排序评测任务第一名经验总结
[24] Blei, David M., Andrew Y. Ng, and Michael I. Jordan. “Latent dirichlet allocation.” Journal of machine Learning research 3.Jan (2003): 993-1022.
[25] Jianfeng Gao, Xiaodong He, and JianYun Nie. Click-through-based Translation Models for Web Search: from Word Models to Phrase Models. In CIKM 2010.
[26] Huang, Po-Sen, et al. “Learning deep structured semantic models for web search using clickthrough data.” Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013.
[27] SimNet .
[28] Guo T, Lin T. Multi-variable LSTM neural network for autoregressive exogenous model[J]. arXiv preprint arXiv:1806.06384, 2018.
[29] Hu, Baotian, et al. “Convolutional neural network architectures for matching natural language sentences.” Advances in neural information processing systems. 2014.
[30] Pang, Liang, et al. “Text matching as image recognition.” Thirtieth AAAI Conference on Artificial Intelligence. 2016.
[31] 非易、祝升等. 大众点评搜索基于知识图谱的深度学习排序实践.
[32] 仲远、富峥等. 美团餐饮娱乐知识图谱——美团大脑揭秘.
[33] Liu, Xiaodong, et al. “Multi-task deep neural networks for natural language understanding.” arXiv preprint arXiv:1901.11504 (2019).
[34] Burges, Christopher JC. “From ranknet to lambdarank to lambdamart: An overview.” Learning 11.23-581 (2010): 81.
[35] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015).
[36] Sanh, Victor, et al. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019).
[37] Jiao, Xiaoqi, et al. “Tinybert: Distilling bert for natural language understanding.” arXiv preprint arXiv:1909.10351 (2019).
[38] Faster Transformer .
作者介绍:
李勇,佳昊,杨扬,金刚,周翔,朱敏,富峥,陈胜,云森,永超,均来自美团 AI 平台搜索与 NLP 部。


