本文将详细解读微软与 OpenAI 合作推出的 ZeRO-2 框架、新的 ONNX Runtime 和超级计算机。
使用海量数据训练模型,已成为现代深度学习应用的一种常态。以 Transformers 及其它预训练模型为代表的一些最新的创新性应用,需要特大型训练框架的支持。此类预训练模型通常被视为人工智能领域的最新突破,由此激发了全球范围引领该领域的一些顶级技术企业间的竞争。在最近的 Build 大会上,微软展示了自身在支持大规模构建和使用大规模预训练模型方面的一些最新举措。
深度学习领域的最新进展,主要围绕着预训练模型和 Transformers。这场运动源自于 Google 提出的著名 BERT 模型,OpenAI GPT-2、微软 Turin-NLG 等特大型架构随后迅速跟进。建立此类模型,不仅需要占用大量计算资源,而且通常还需要在架构上针对大规模训练操作做出优化。由于其新颖性,主流深度学习框架尚未包含此类架构。微软的最新举措,全面代表了深度学习社区在简化创建和访问大规模模型上的进展。下面择其重点进行概述。
Zero-2 和 DeepSpeed
微软于今年年初开源了 DeepSpeed 的首个版本。DeepSpeed 是一种优化大规模训练的框架,是支持微软 Turing-NLG 模型打破记录的后台基础框架。在发布版中,包括了一个称为“ZeRO”(零冗余优化器,Zero Redundacy Optimizer)的优化模块。从概念上讲,ZeRO 寻求模型并行和数据并行的中间点,致力于最大化模型的可扩展性。ZeRO 的最大优点,是无需重构代码即可支持在内存中运行大型深度学习模型。这是通过优化模型内存的使用方式而实现的。就此而言,ZeRO 可视为一种深度学习模型的内存优化方法。
作为 ZeRO 的第二版,ZeRO-2 相比第一版做了多处创新。其中涉及深度学习模型内存使用的多个方面,包括激活内存、碎片内存和模型状态内存。
模型状态内存(Model State Memory): ZeRO-2 优化了保存模型状态的内存,达到相比传统的数据并行方法降低内存使用 8 倍。所有深度学习模型的状态,可归为分区优化器状态、梯度和参数这三个基本过程。在 ZeRO 第一版中,优化了分区优化器状态的内存使用,达到比传统方法降低内存使用 4 倍。ZeRO-2 在该方法上做了扩展,优化了梯度计算过程的内存占用,进一步降低内存使用 2 倍。
激活内存(Activation Memory):即便优化了模型状态内存,激活函数依然可导致瓶颈。激活函数计算位于前向过程中,用于支持后向过程。ZeRO-2 引入了一种将计算过程加载到主机 CPU 的激活分区技术,消除了内存瓶颈隐患。
碎片内存(Fragmented Memory):在一些情况下,深度学习模型的低效是由于碎片所导致的,这些碎片的生成,源自于模型中各个张量的不同生命周期。ZeRO-2 通过管理不同张量生命周期的内存使用全过程,消除了低效问题。
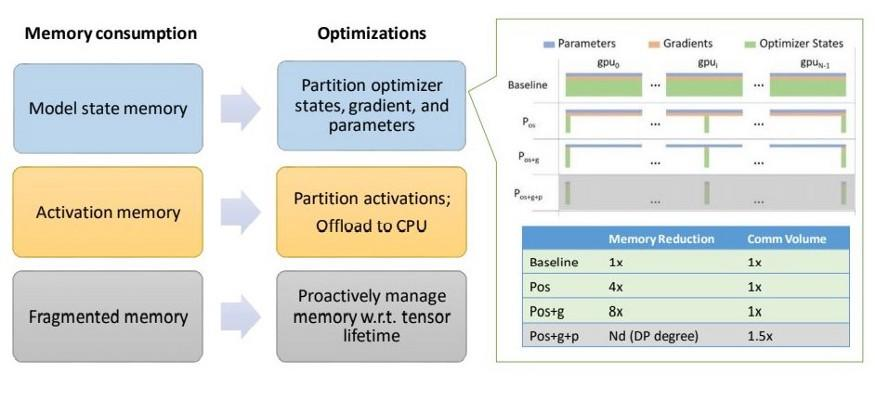
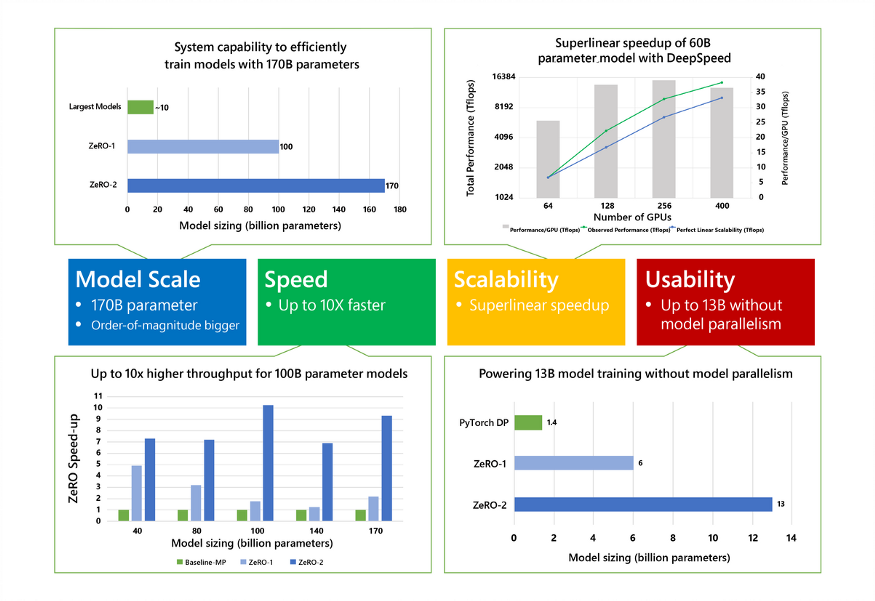
不同于其它方法中大多通过将训练分布在各个 GPU 上进行优化,ZeRO-2 的一个最显著创新就是支持单个 GPU 粒度的内存优化。ZeRO-2 团队展示了使用单个 GPU 达到在 44 分钟内训练 Google BERT 版本,明确给出该优化的价值所在。下图是 ZeRO-2 对比以往方法的改进情况。
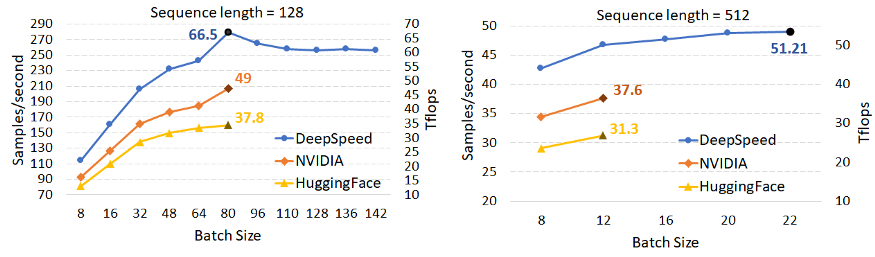
此外,如下图所示,在支持具有数十亿参数模型的能力、实现更高通量和高速度、每个 GPU 和跨 GPU 集群上的扩展性、单个 GPU 上训练超大模型等方面,ZeRO-2 同样展现了其优势所在。
ZeRO-2 + ONNX Runtime
ONNX Runtime 是一种支持不同机器学习框架间互操作的开源框架。机器学习互操作性的一个关注点,在于其是否适用于超大模型。ONNX 可直接用于决策树,但其是否同样可用于具有数十亿参数的模型?
为优化 ONMX 模型的训练和内存使用,微软决定在 ONNX Runtime 中添加 DeepSpeed 和 ZeRO-2。下图展示了在一些当前全球最大的预训练模型上的测试结果,包括在 Visual Studio 中的 GPT-2、在 Office 365 中的 Turing-NLG,以及 Bing 中具有 5 亿参数的大型 transformer。

AI 优先的超级计算机
基础架构是实现大规模预训练模型的关键。微软和 OpenAI 的科研人员通过合作,开发了专用于大型深度学习工作负载的超级计算机。该超级计算机在单个系统的基础架构内,不可思议地集成了超过 28.5 万个 CPU 内核、1 万个 GPU,每台 GPU 服务器的网络互连能力达每秒 400 千兆位。
这台微软 -OpenAI 合作超级计算机所使用的基础设施,已跻身全球超级计算机排名的前五位。更值得关注的是,这台超级计算机针对 AI 工作负载做了优化。从这个意义上讲,该超级计算机设计用于执行 Turing-NLG、BERT 等大型预训练模型。微软将新的超级计算机以 Azure 云的服务形式提供给开发人员。
总 结
未来几年中,人工智能市场最值得关注的一个趋势,就是大规模人工智能主导地位之争。现在 DeepSpeed-ZeRO-2、ONNX Runtime 和新型 OpenAI 超级计算机等举措,表明微软在该竞赛中领先迈出了坚实的一步。
原文链接:
https://medium.com/swlh/inside-microsofts-new-frameworks-to-enable-large-scale-ai-953e9a977912


