最近工作上遇到一个“神奇”的问题,或许对大家有帮助,因此形成本文。

图片来自 Pexels
问题大概是,我有两个表 TableA,TableB,其中 TableA 表大概百万行级别(存量业务数据),TableB 表几行(新业务场景,数据还未膨胀起来)。

语义上 TableA.columnA=TableB.columnA,其中 columnA 上建立了索引,但查询的时候确巨慢无比,基本上到 5-6 秒,明显跟预期不符合。
下面我以一个具体的例子来说明,模拟其中的 SQL 查询场景。
场景重现
user_info 表,为了场景尽量简单,我只 mock 了其中的三列数据。user_score 表,其中 uid 和 user_info.uid 语义一致。
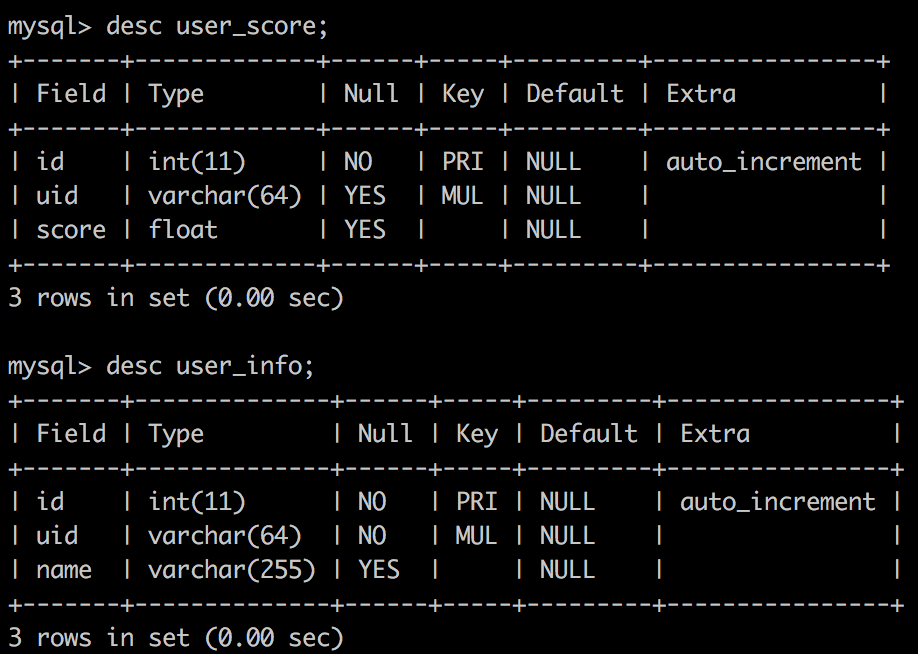
其中数据情况如下, 都是很常见的场景:

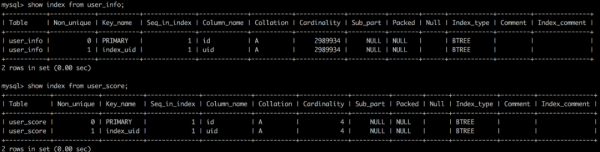
索引情况如下图:
查询业务场景:已知 user_score.id,需要关联查询对应 user_info 的信息,(大家先忽略这个具体业务场景是否合理哈)。
那么对应的 SQL 很自然的如下:
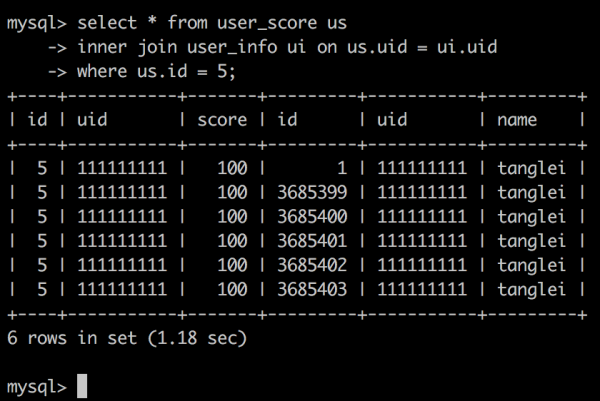
请忽略其中的数据,我刚开始 mock 了 100W,然后又重复导入了两遍,因此数据有一些重复。
300W 数据,最后查询出来也是 1.18 秒,按道理应该更快的,老规矩 explain 看看啥情况?

发现 user_info 表没用上索引,全表扫描近 300W 数据?现象是这样,为什么呢?
你不妨思考一下,如果你遇到这种场景,应该怎么去排查?

我当时也是“一顿操作猛如虎”,然并卵?尝试了什么多种 SQL 写法来完成这个操作。
比如更换 Join 表的顺序(驱动表/被驱动表),再比如用子查询。最终,还是没有结果。但直接单表查询写 SQL 确能用上索引。
问题解决
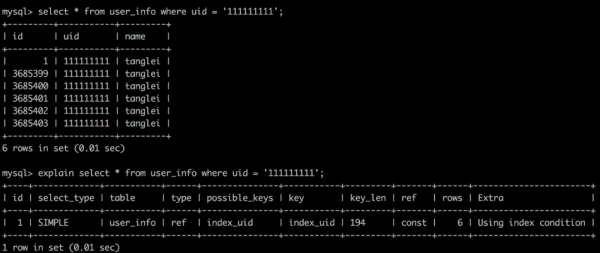
尝试更换检索条件,比如更换 uid 直接关联查询,索引仍然用不上,差点放弃了都。
在准备求助 DBA 前,我看了下表的建表语句:

完全有理由怀疑因为字符集不一致的问题导致索引失效的问题。
于是修改了小表(真实线上环境可别乱操作)的字符集与大表一致,再测试下:
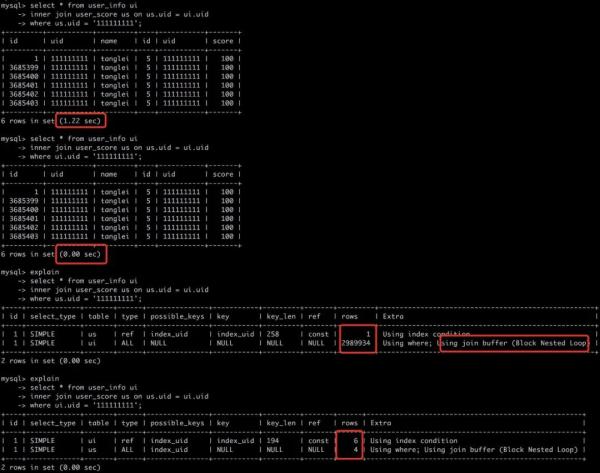
mysql> select * from user_score us -> inner join user_info ui on us.uid = ui.uid -> where us.id = 5; +----+-----------+-------+---------+-----------+---------+ | id | uid | score | id | uid | name | +----+-----------+-------+---------+-----------+---------+ | 5 | 111111111 | 100 | 1 | 111111111 | tanglei | | 5 | 111111111 | 100 | 3685399 | 111111111 | tanglei | | 5 | 111111111 | 100 | 3685400 | 111111111 | tanglei | | 5 | 111111111 | 100 | 3685401 | 111111111 | tanglei | | 5 | 111111111 | 100 | 3685402 | 111111111 | tanglei | | 5 | 111111111 | 100 | 3685403 | 111111111 | tanglei | +----+-----------+-------+---------+-----------+---------+ 6 rows in set (0.00 sec) mysql> explain -> select * from user_score us -> inner join user_info ui on us.uid = ui.uid -> where us.id = 5; +----+-------------+-------+-------+-------------------+-----------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+-------------------+-----------+---------+-------+------+-------+ | 1 | SIMPLE | us | const | PRIMARY,index_uid | PRIMARY | 4 | const | 1 | NULL | | 1 | SIMPLE | ui | ref | index_uid | index_uid | 194 | const | 6 | NULL | +----+-------------+-------+-------+-------------------+-----------+---------+-------+------+-------+ 2 rows in set (0.00 sec)
果然 Work 了。
挖掘根因
其实深究原因,就是网上各种 MySQL 军规/规约所提到的, “索引列不要参与计算”。
这次这个 case,如果知道 explain extended+show warnings 这个工具的话,(以前都不知道 explain 后面还能加 extended 参数),可能就尽早“恍然大悟”了。(最新的 MySQL 8.0 版本貌似不需要另外加这个关键字)
看下效果:(啊,我还得把字符集改回去)
mysql> explain extended select * from user_score us inner join user_info ui on us.uid = ui.uid where us.id = 5; +----+-------------+-------+-------+-------------------+---------+---------+-------+---------+----------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+-------+-------------------+---------+---------+-------+---------+----------+-------------+ | 1 | SIMPLE | us | const | PRIMARY,index_uid | PRIMARY | 4 | const | 1 | 100.00 | NULL | | 1 | SIMPLE | ui | ALL | NULL | NULL | NULL | NULL | 2989934 | 100.00 | Using where | +----+-------------+-------+-------+-------------------+---------+---------+-------+---------+----------+-------------+ 2 rows in set, 1 warning (0.00 sec) mysql> show warnings; +-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Note | 1003 | /* select#1 */ select '5' AS `id`,'111111111' AS `uid`,'100' AS `score`,`test`.`ui`.`id` AS `id`,`test`.`ui`.`uid` AS `uid`,`test`.`ui`.`name` AS `name` from `test`.`user_score` `us` join `test`.`user_info` `ui` where (('111111111' = convert(`test`.`ui`.`uid` using utf8mb4))) | +-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)索引列参与计算了,每次都要根据字符集去转换,全表扫描,你说能快得起来么?
至于这个问题为什么会发生?综合来看,就是因为历史原因,老业务场景中的原表是假 utf8,新业务新表采用了真 utf8mb4。
①考虑新表的时候,忽略和原库字符集的比较。其实,发现库里面的不同表可能都有不同的字符集,不同人建的时候可能都依据个人喜好去选择了不同的字符集。由此可见,开发规范有多重要。
②虽然知道索引列不能参与计算,但这个场景下都是相同的类型,varchar(64) 最终查询过程中仍然发生了类型转换。因此需要把字段字符集不一致等同于字段类型不一致。
③如果这个 case,利用 fail-fast 的理念的话,发现不一致,直接不让 join 会不会更好?(就像 char v.s varchar 不能 join 一样)
说明:本文测试场景基于 MySQL 5.6,另外,本文案例只是为了说明问题,其中的 SQL 并不规范(例如尽量别用 select * 之类的),请勿模仿(模仿了我也不负责)。
最后留一个思考题供讨论,欢迎留言说出你的看法。
你能解释如下情况吗?查询结果表现为何不一致?注意一下 SQL 的执行顺序,查询优化器工作流程,以及其中的 Using join buffer(Block Nested Loop)。
可以多看看 MySQL 官方手册深入了解背后的过程和原理:
https://dev.mysql.com/doc/refman/5.6/en/
作者:唐磊
简介:清华学渣,目前就职阿里云,曾就职于大疆,宜信,Tencent,友盟。
编辑:陶家龙
出处:转载自公众号程序猿石头(ID:tangleithu)


